半年前翻了 Systems Performance(性能之巅)的一小部分,现在进一步阅读并做点复查用的笔记。
目前打算是分成两篇,一篇介绍基本理论,另一篇介绍工作流。本篇为工作流。
注意这里提到的是系统性能存在异常时的工作流,不涉及稳定性和常规性能优化。
保命声明:显然这是一个很有深度的话题,然而笔者的水平只能浅到不能再浅了……
免责声明:这是一篇未完工的文章!
用工具观测资源
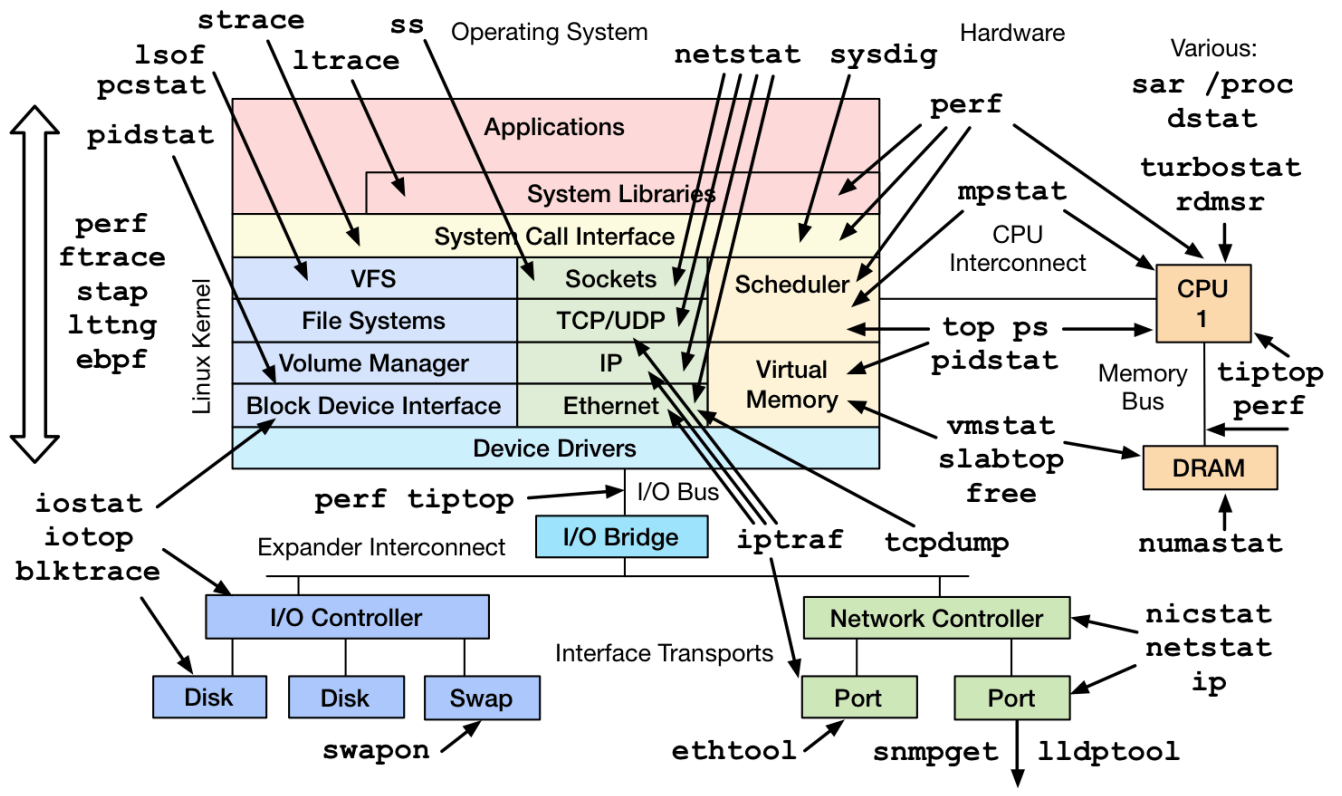 非常有名的工具大全
非常有名的工具大全
上一篇文章介绍用于性能分析的 USE 方法:从资源的利用率、饱和度和错误去看待性能。是否存在性能问题主要看饱和度和错误:若存在性能问题,必有过饱和或者错误;若未存在性能问题,可以通过排队论对利用率的临界点进行预测。再直白点说,如果在系统中想要获取某一项资源,但是获取的过程发生了停顿等待(排队)的行为,那就是存在性能问题。
观测资源则需要用到工具。但是如上图所示,工具(还有指标)的选择非常多,不同背景的开发者对资源的划分也有不同的见解,因此还是要准备一份适合自己的工作流。
NOTE: 上一篇文章也提到 PSI 是一个非常好用的系统压力指标,可以避免各种工具的学习成本,这里不再重复介绍了。
CPU
CPU 的主要性能指标有:平均负载(load average)、CPU 使用率(CPU usage,%CPU)和IPC(instructions per cycle)。
平均负载跟踪处于 TASK_RUNNING (R) 加上 TASK_UNIERRUPTED (D) 状态的任务数目,并且按照每 1 分钟、5 分钟和 15 分钟的粒度给出三个平滑处理过的数值。这些数据用于动态观察系统整体负载(计算负载和 IO 负载)的变化趋势。(这里负载指的是需要运行处理但是可能允许排队的任务。)有两个诊断用的经验方法:理想状态认为数值低于 CPU 数目;高于 70%CPU 数目则认为是高负载。该指标可以使用 uptime、top 或者 cat /proc/loadavg 命令获取。如果需要统计分离的 R 状态和 D 状态的任务数目,可以使用 dstat -p 命令获取。
系统级别的 CPU 使用率划分了不同类型的 CPU 时间占比,包含 usr、nice、sys、iowait、irq、soft 和 idle 等负载类型,按照百分比显示。on-CPU 相关需要关注前三项,如果是 usr 低占比的同时 sys 高占比,可能存在两种情况:一是用户层的代码足够好,只剩下高占比的系统调用;二是用户层的代码足够差,有大量使用不当的系统调用。该指标可以使用 top、dstat -c 或者 cat /proc/stat | grep cpu(需解析)命令获取。每 CPU 级别可以直接使用 mpstat -P ALL、sar -P ALL 1 或者 top 交互面板按 1 命令获取。
任务级别的 CPU 使用率计算非空闲状态的 CPU 时间(non-idle time)占比,其结果仅有一个百分比数值,这里的非空闲时间指的是系统时间(stime)加上用户时间(utime)。该指标可以使用 top 命令获取。
IPC 是每时钟周期所执行的平均指令数。有一种说法认为前面提到的非空闲时间不等价于繁忙时间,事实上还可能包含了停顿时间(iowait),也就是不应该使用 CPU 使用率来衡量 CPU 繁忙程度,而是使用 IPC 来衡量。(需要注意系统 CPU 使用率显示可以细化到多种分类,iowait 是可以单独展示的。而任务的 CPU 使用率只显示一个百分比,是否包含 iowait 还取决于工具的版本或算法,这里确实是个含糊的地方。)IPC 数值的简单划分方式是:IPC 小于 1.0 很可能是出现了停顿问题(off-CPU),而大于等于 1.0 则至少可认为是正常情况。如果需要更精准的划分,可以自行定制。该指标可以使用 perf stat(默认是 system wide 模式,即 -a)或者 tiptop 命令获取。
Here’s how you can get a value that’s custom for your system and runtime: write two dummy workloads, one that is CPU bound, and one memory bound. Measure their IPC, then calculate their mid point.
Memory
内存的主要性能指标有:内存利用率(%MEM)、页面回收效率(%vmeff)和任务的内存映射区域(smaps)。
内存利用率是容量意义上的利用率。系统级别的内存利用信息都集中在 meminfo,其可用内存份额为 MemAvailable(一个估算值),系统的利用率可以按照 (MemTotal - MemAvailable) / MemTotal 计算;任务级别的内存利用率则是按照 RSS 计算。这些内容的解析可以看这篇文章。该指标可以使用 top、free 或者 cat /proc/meminfo 命令获取。
页面回收效率跟踪 kswapd 页面回收和直接页面回收的压力情况。因为 Linux 系统本身善用页面缓存(page cache),所以内存利用信息里面统计的 MemFree 和 MemAvailable 存在一定数值差距。但是当内存使用存在压力时,可用内存份额是否完全释放出页面缓存作为救急用内存,这还需要观察 %vmeff (= pgsteal / (pgscank + pgscand)) 即页面回收效率。从 man page 可以了解到,理想状态为 100%,但是降低到一定程度如 30% 就可能是 memory bound。该指标可以使用 sar -B 命令获取。
任务内存映射区域可以按照进程的每个内存区域进行内存信息统计。最简单的分析方法就是查看数值是否符合程序实现的预期。该指标可以使用 cat /proc/[pid]/smaps 命令获取。
NOTE: 内存的压力有一部分来自缓存,尤其是程序自身实现的缓存,这部分的缓存让系统误判为是一时无法回收的资源。因此在内存利用率上,我们能看到的系统层面的内存统计信息不一定是事实正确的。比如 meminfo 提示可用内存份额已经小于 10MB,但是实际上有高达 10GB 的程序缓存可以直接释放,这是系统层面无法直接得知的信息。因此,这方面的分析我觉得需要程序自行实现缓存信息统计的工具或命令。
TODO: 关于 PSS 和 RSS 的选择。工具一般提供 RSS 作为默认选择,但是 Android 平台经常是以 PSS 的形式给出。我也不知道谷歌的想法……调研待办。
Disk
通常 IO 设备(包括硬盘)有三个主要性能指标:IOPS、吞吐量和延迟。虽然指标的含义人尽皆知,但是我寻思这些指标是写到 PPT 里给大老板看的。
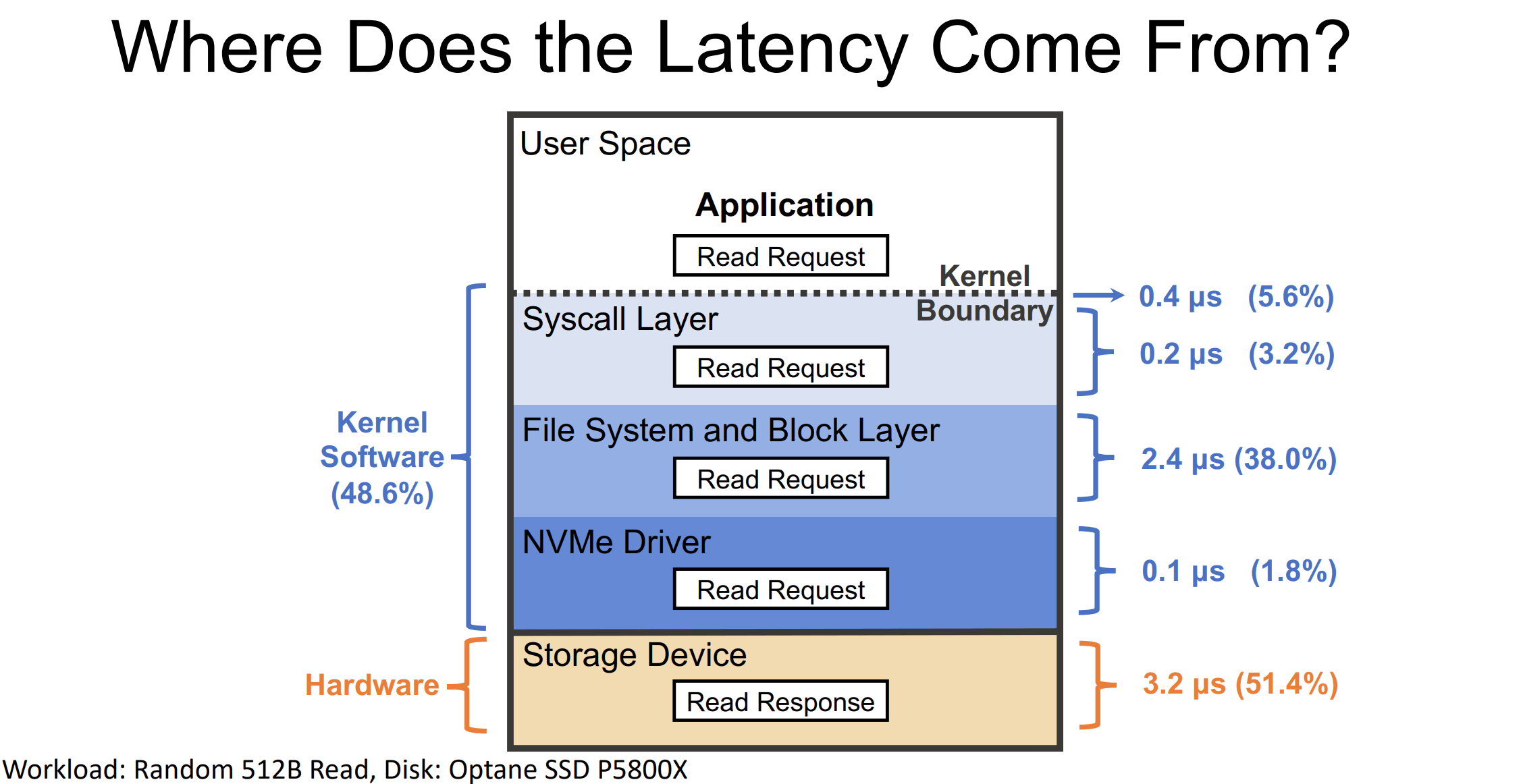 延迟的粒度
延迟的粒度
对于系统性能分析来说,这里也许有进一步讨论的价值:
- 从 IO 特征的角度来看,吞吐量描述了不同的 IO 块大小乘上对应的 IOPS 的累计结果。反过来说,吞吐量作为计算后的结果其实忽视了 IO 特征中块大小的分布信息。
- 延迟指标也有粒度上的问题,见上图,如果 IO 生命周期只有一个从开始到结束的延迟统计信息,那就难以发现是哪一个层面出现的性能问题。
- 无论是 IOPS、吞吐量还是延迟,它们都是针对已经完成的 IO 操作而言的,还没考虑到尚未完成的 IO 操作,因此还需要观察排队压力情况,也就是 IO 的队列长度。
- 同样是 IO 特征,不同的业务场景会影响到 IO 的访问模式。如果存在异常的读写比例倾斜,我们可以直接定位是 IO 性能问题,节省对其它指标的分析时间。
上面加粗的文字部分是需要额外考虑的性能指标。
IO 块大小分布的获取方式很多:可以使用 bpftrace.biostacks 命令,输出还包含了调用的 IO 栈路径;也可以使用 bpftrace.bitesize 命令,输出包含了调用者的进程 ID。
IO 队列长度的获取可以使用 iostat -x 或者 sar -d 命令。aqu-sz 即所求。
IO 访问模式的获取可以使用 bcc.biopattern 命令,输出 %RND 和 %SEQ 比例;以及使用 iostat -x 命令,读取 r/s 和 w/s(按请求个数),rkB/s 和 wkB/s(按请求大小)。
延迟粒度如果需要简单获取,可以使用 bpftrace.biolatency 命令,提供 IO 的延迟时间和对应的 IO 个数汇总;复杂的就需要使用 blktrace+blkparse+btt 工具,会按照下表划分 IO 栈内部的延迟时间,其中 D2C 和 Q2C 是较为重要的指标,分别表示 IO 栈的硬件服务时间和 IO 栈的完整响应时间(等同于 bpftrace.biolatency 结果),另外 Q2G 也代表了 IO 排队的情况。
blkparse的延迟统计粒度:
Q------->G------------>I--------->M------------------->D----------------------------->C
|-Q time-|-Insert time-|
|--------- merge time ------------|-merge with other IO|
|----------------scheduler time time-------------------|---driver,adapter,storagetime--|
|----------------------- await time in iostat output ----------------------------------|
Q2Q — time between requests sent to the block layer
Q2G — time from a block I/O is queued to the time it gets a request allocated for it
G2I — time from a request is allocated to the time it is Inserted into the device's queue
Q2M — time from a block I/O is queued to the time it gets merged with an existing request
I2D — time from a request is inserted into the device's queue to the time it is actually
issued to the device
M2D — time from a block I/O is merged with an exiting request until the request is issued
to the device
D2C — service time of the request by the device
Q2C — total time spent in the block layer for a request
You can deduce a lot about a workload from the above table. For example, if Q2Q is much
larger than Q2C, that means the application is not issuing I/O in rapid succession. Thus,
any performance problems you have may not be at all related to the I/O subsystem.
If D2C is very high, then the device is taking a long time to service requests. This can
indicate that the device is simply overloaded (which may be due to the fact that it is a
shared resource), or it could be because the workload sent down to the device is sub-optimal.
If Q2G is very high, it means that there are a lot of requests queued concurrently. This
could indicate that the storage is unable to keep up with the I/O load.
!!!!! WORK IN PROGRESS !!!!!
!!!!! WORK IN PROGRESS !!!!!
!!!!! WORK IN PROGRESS !!!!!
还有好多内容要写,比如上面只提了块设备用途的工具,bcc 还提供了 [fs_name]slower 工具直接定位到具体文件系统中超过一定时长的操作(如 f2fsslower);或者简单粗暴地找出暴力发出 IO 的 iotop 等等。其他类型的工具也没整理好,容我歇一会 orz
References
Systems Performance, 2nd Edition
Linux Load Averages: Solving the Mystery – Brendan Gregg’s Blog
CPU Utilization is Wrong – Brendan Gregg’s Blog
top 中 CPU 使用率计算原理 – 知乎
sar man page on SuSE – Polarhome
内存管理概览 – Android Developers
Block I/O Layer Tracing: blktrace – Hewlett-Packard Company
6.3. Tools – Red Hat Customer Portal
blktrace 分析 IO – Bean Li
Block Layer Observability with bcc-tools – Oracle Linux Blog
tracepoints instead of kprobes in biolatency.bt – bpftrace
XRP: In-Kernel Storage Functions with eBPF – USENIX