半年前翻了 Systems Performance(性能之巅)的一小部分,现在进一步阅读并做点复查用的笔记。
目前打算是分成两篇,一篇介绍基本理论,另一篇介绍工作流。目标是内容尽可能精简。
保命声明:显然这是一个很有深度的话题,然而笔者的水平只能浅到不能再浅了……
USE
性能分析方法众多,个人觉得 USE method 最值得学习。USE method 是从资源的角度去看待性能。
定义
USE 分别指的是资源的利用率(utilization)、饱和度(saturation)以及错误(errors)。
利用率定义有两种,时基利用率(time-based)和容基利用率(capacity-based):
- For resources that service requests, utilization is a measure of how busy a resource is, based on how much time in a given interval it was actively performing work.
- For resources that provide storage, utilization may refer to the capacity that is consumed (e.g., memory utilization).
饱和度定义:The degree to which a resource has queued work it cannot service.
错误是字面意思。
量化
时基利用率可能允许到达 100%,此时只意味着可能存在性能下降,还需要通过饱和度去判断。
相比之下,容基利用率不允许到达 100%,因为此时无法接受更多的任务,必然处于饱和状态。
任何饱和或错误均不得存在。饱和意味着服务不可用时引起的排队,这是易于理解的。这里补充一下对错误的理解:在部分系统中,服务不可用时可能无法进行排队,因此只能返回错误。
 图 1:没有利用到并行的四服务队列(Q)系统
图 1:没有利用到并行的四服务队列(Q)系统
 图 2:采样窗口(T1-T9)显示低占用,但有 2 个饱和(S)任务
图 2:采样窗口(T1-T9)显示低占用,但有 2 个饱和(S)任务
关于时基利用率还需要进一步说明:
- 允许 100% 利用率存在,是因为此时并不意味着过饱和:构造一个多服务队列的示例(见上图 1),尽管纵向看是所有时间都处于繁忙占用状态,但实际每时刻是允许并行处理的。
- 同时 70% 利用率可认为是饱和临界点。这是基于排队论中单服务队列且固定服务时间的 M/D/1 模型得出的结论,后面有简单证明。
- 以上仅适合服务随机分布的情况。如图 2,瞬时高峰也可能导致低利用率存在过饱和现象。
例程

附:M/D/1 响应时间的计算
设服务时间 \(s\),响应时间 \(r\),利用率 \(ρ\)。
M/D/1 的计算公式为:\(r = \frac{s(2-ρ)}{2(1-ρ)}\)。
由于模型是固定服务时间,因此 \(s\) 是一个常数。设 \(s = 1ms\)可以绘制 \(r\) 和 \(ρ\)的关系。
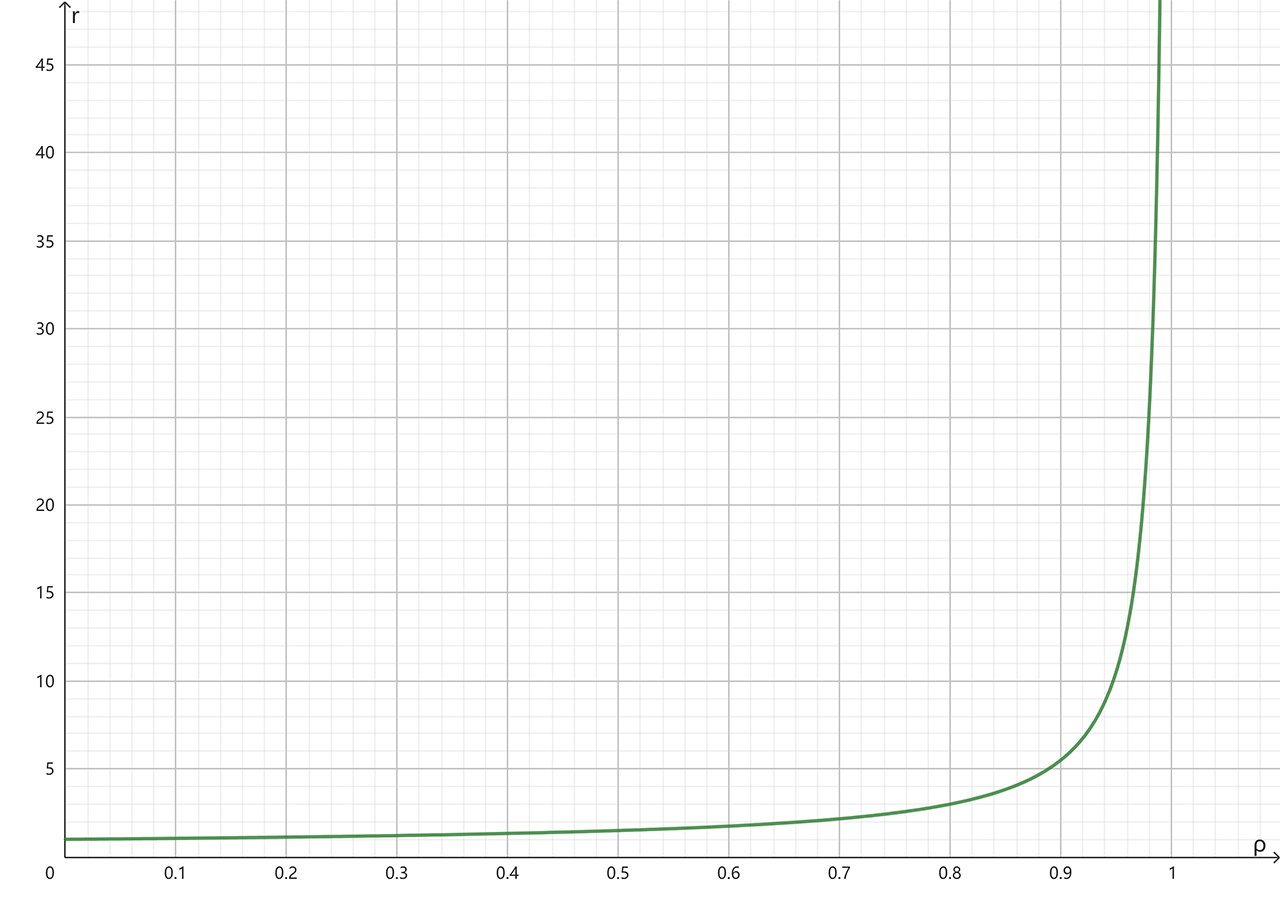 横坐标为利用率,纵坐标为响应时间
横坐标为利用率,纵坐标为响应时间
当利用率达到 67% 时,响应时间翻倍为 \(2ms\),往后明显剧增。这就是~70% 作为临界点的依据。
术语
- Throughput: The rate of work performed.
- Lantency: A measure of time an operation spends waiting to be serviced.
- Bandwidth: Bandwidth refers to the maximum possible throughput.
- Response time: The time for an operation to complete.
- AbaAba…
名词其实没啥好说的,因为表达多是需要看上下文。但为了严谨,有时候还是需要准确的描述。比如响应时间,它的定义是包含了等待时间和服务时间。那么在没有上下文的时候“延迟”是意味着哪个时间?根据定义,延迟只算等待时间。
资源
既然 USE 是资源角度去看待问题,那总得归纳一下有什么资源。
资源的细分打算放到工作流结合具体工具再去详解。这里作为一个总览。
开销
资源的正常开销至少要心中有数。基于上述资源可展示一些常规数据。
HW
Systems Performance 2.3.2 给出了具体的系统延迟,这是 2020 年的硬件数据。
NOTE: 笔者对比了 2013 年的第一版数据,确认作者是有更新的,而不是原样 copy 到第二版。
| 事件 | 延迟 |
|---|---|
| CPU 周期 | 0.3ns |
| L1 访问 | 0.9ns |
| L2 访问 | 3ns |
| L3 访问 | 10ns |
| 内存访问 | 100ns |
| SSD IO | 10-100μs |
| HDD IO | 1-10ms |
| Network IO | 国情第一,数据第二 |
笔者身为退役垃圾佬也自测和收集过一些硬件数据,可以作为进一步的参考:
| 设备 | 事件 | 延迟 |
|---|---|---|
| 自购 AMD Ryzen7 5800H | CPU 周期* | 0.24ns |
| 自购 AMD Ryzen7 5800H | L1 访问 | 1ns |
| 自购 AMD Ryzen7 5800H | L2 访问 | 3ns |
| 自购 AMD Ryzen7 5800H | L3 访问 | 12ns |
| 外设大厂 DDR5 6000 内存条 | 内存访问 | 100ns |
| 最强末代傲腾 P5800X | 4k 平均延迟 | 5μs |
| 大船货 CM5-V NVMe SSD | 4k 写延迟 | 10μs |
| 大船货 CM5-V NVMe SSD | 4k 读延迟 | 100μs |
| 磨损 3 年的 HFS512GDE9X084N | 4k 写延迟 | 30μs |
| 磨损 3 年的 HFS512GDE9X084N | 4k 读延迟 | 70μs |
| ⭐⭐⭐ S23 Ultra UFS 4.0 | 4k 写延迟 | 50μs |
| ⭐⭐⭐ S23 Ultra UFS 4.0 | 4k 读延迟 | 100μs |
| 自购丐版 iPhone 14 Pro | 4k 平均延迟 | 110μs |
| 黑科技 Exos X20 HDD | 4k 平均延迟 | 4ms |
NOTE: CPU 周期从现代 CPU 的角度来看很复杂,而上表 5800H 的周期延迟是基于 PMU 统计作为计算密集型任务的 Linux 内核编译过程得出的数据。顺便一提,该场合 IPC=1.61。
SW
虽然算不上严格的 microbenchmark,笔者没事也收集了一些软件层的跑分性能:Caturra000/Snippets/perf – Github。
| 事件 | 延迟 |
|---|---|
| 系统调用 | 44ns |
| 系统调用(经典) | 145ns |
| 系统调用(vdso) | 2ns |
| 进程切换(亲和) | 1150ns |
| 线程切换(亲和) | 870ns |
| 进程切换(非亲和) | 3000ns |
| 线程切换(非亲和) | 2500ns |
| 函数调用 | 0.4-2ns |
| 函数调用(cache miss) | 6ns+ |
| 内存分配(ptmalloc,1-128 字节) | 8-20ns |
| 内存分配(mmap,1-128 字节) | 1000ns+ |
| CAS(同 CPU 内) | 7ns |
| Lock(同 CPU 内) | 15ns |
| CAS(同 core 内) | 18ns |
| CAS(跨 core) | 47ns |
| CAS(跨 socket) | 442ns |
NOTE1: 原子操作与锁操作的数据节选自 perfbook。Lock 的数据当作 2 次 CAS 看待即可。
NOTE2: 由于笔者有多台测试设备,数据并没做归一化处理。实际差异不大,了解量级即可。
PSI
实际上,饱和的别名用词是压力(pressure)。并且在 Linux 内核中,PSI(Pressure Stall Information)是一个通用的压力指标。
为什么要介绍 PSI?Systems Performance 虽然给出了不少的饱和测量方式,但可以总结得出,PSI 适用面最广。下表节选自原书 Table 2.6:
| Resource | Type | Metric |
|---|---|---|
| CPU | Saturation | Run queue length, scheduler latency, CPU pressure (Linux PSI) |
| Memory | Saturation | Swapping (anonymous paging), page scanning, out-of-memory events, memory pressure (Linux PSI) |
| Storage device I/O | Saturation | Wait queue length, I/O pressure (Linux PSI) |
那么基于前面的理论,是不是 PSI 统计有任意非零数均可认为是性能问题?这方面可以参考一个成熟的系统的实践,比如 AOSP 也使用 PSI 作为一种饱和检测手段。监听多大的数值以及如何消除饱和等细节可过目之前写的文章:AOSP 的进程管理。简单来说就是轻微容错和多级反馈。
NOTE: 由于 AOSP 的特定用途,其实并没有精准到每进程的统计粒度。我一直在想,为什么 PSI 只提供 some 而不提供 who?难道通用的办法总得在功能上做减法?
工具
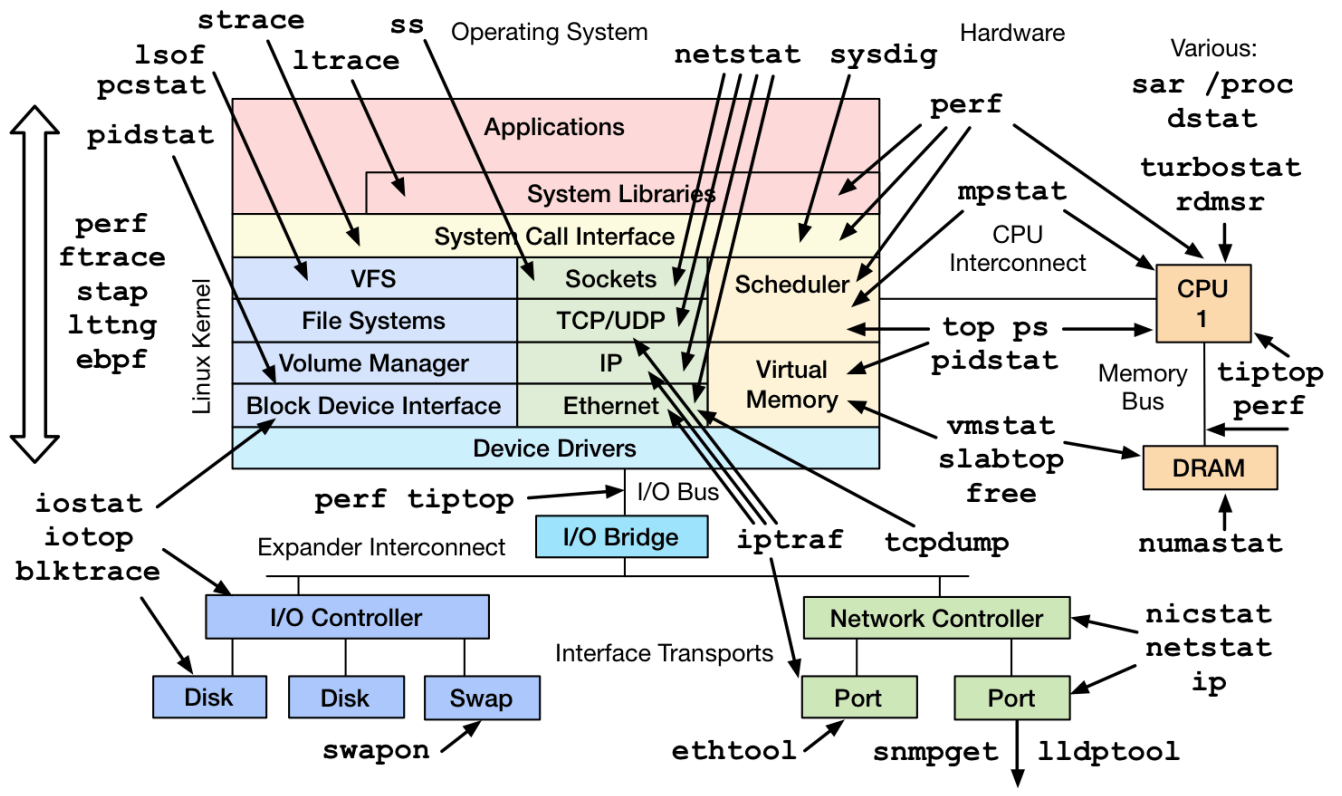 非常有名的工具大全
非常有名的工具大全
对于更多的利用率和饱和度统计,作者从第四章起就给出了大量的工具介绍。(加上时下流行的 eBPF,衍生的工具是非常非常多啊 orz)
很显然光靠一个图是解决不了问题的……现实中能起到的作用是:依照前面的例程,我先判断哪个资源出问题了,就从这个图里找工具,统计对应的 USE。
笔者之前也搜集过一些零零散散的使用 tips,其中一些工具链的选项挺有意思(书里似乎较少涉及这方面的内容,可能是因为选项偏向优化而不是分析),后续会花点时间总结到工作流中。
「逆转裁判」
这篇文章本质上是从资源的角度进行自底向上的推理分析,有没有自顶向下的办法来分析性能?有的,比如基于微架构视角的自顶向下性能分析方法,参考上一篇文章:[论文阅读] A Top-Down Method for Performance Analysis。
References
Systems Performance, 2nd Edition
perfbook (Is Parallel Programming Hard, And, If So, What Can You Do About It?)
Exos X20 Data Sheet
The Samsung 980 PRO PCIe 4.0 SSD Review: A Spirit of Hope
ThinkSystem Kioxia CM5-V Mainstream NVMe PCIe 3.0 x4 Flash Adapters
Samsung Galaxy S23 Ultra Review
ThinkSystem P5800X Write Intensive NVMe PCIe 4.0 SSDs