前言
保命声明:标题是原封不动从 paper 抄过来的,非本人立场
mmap 和 read/write 谁更适合文件 IO 已经是个日经问题了,与其嘴炮不如看下别人的调研和求证,这样子嘴炮就可以更加有理有据了!
这篇论文主要探讨的是 mmap 应用于 DBMS 中作为 buffer pool 是否合适的问题,但也指出了 mmap 的潜在问题,所以非 DB 选手(比如我)也是适合看的
先说结论
- 通过实验的方式,对比
mmap和传统的文件 IO 方法在不同的访问模式和存储设备上的性能差异,发现mmap在大多数情况下没有优势 mmap的性能问题在 IO 本身之外- 至少给出了 2 个
mmap的不适用场景:- 对于比物理内存本身还大的 workload(比如数据库的 buffer),
mmap不适合 - 对于高吞吐的存储设备来说,
mmap不具有扩展性(跟不上硬件)
- 对于比物理内存本身还大的 workload(比如数据库的 buffer),
- 也给出了 2 点可能的适用场景:
- 工作集比内存小,而且 IO 是只读类型
- 需要赶时间做出产品,允许把 cache 管理的职责交给 OS
另外有些结论是只关乎 DB 的,我没有列在这里,感兴趣看原文吧
mmap 简单介绍
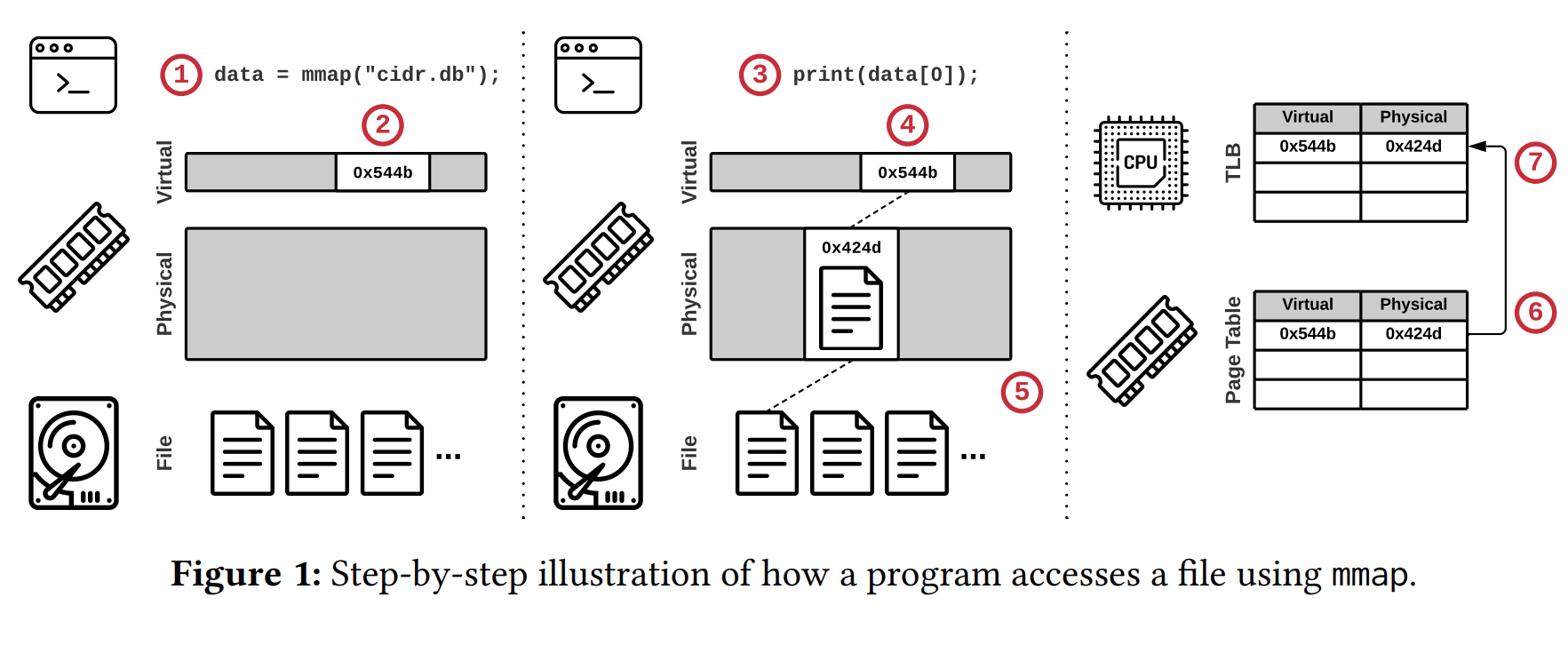
先做简单的 mmap 过程解释:
- 当 userspace 调用
mmap时,内核返回一片新建的地址空间起始地址的指针给你 - 其实这时候仅仅是 kernel 只搞定了虚拟地址空间(在内部分配了一个
vma),即“只分配,不映射”(文件到物理内存地址) - 当你真的要通过地址空间来访问文件的时候
- 即“接触”到对应的虚拟地址,但发现没有映射
- 将会引起 page fault,对应的
handler会在此时才把文件映射到物理内存当中 - 此时已经建立了 virutal 到 physical 的关系,理应也在页表加上对应的 PTE
- 为了加速后续访问,TLB 也会加上对应的 PTE 映射
广告 插播一下:若干年前我也翻过 mmap 的源码,虽说是翻了点皮毛,感兴趣的也可以去看下:
理论上的优势
接口优势
mmap 的独特魅力是把内存操作和外存操作都以统一的方式进行管理
也就是说对一个内存地址进行读写操作根本不需要知道它是内存本身还是外存映射出来的
这在 design 层面上就是把 cache 管理的职责都交给了 OS 去打理:应用层本身就只需关心应用层的事情
性能优势
对比传统 IO 接口,mmap 理应性能突出,至少它在实现上是:
- 不会产生显式的系统调用开销
- 避免了重复的 buffer(从 user 到 kernel 的)拷贝
“商业优势”
甚至在 80 年代,一些 DB 厂商还以使用了 mmap 作为高性能的宣传卖点
甚至更早以前,mmap 的实现是个商业机密
总而言之:你不用,你就是慢人一步
实际上的缺陷
接口问题
首先,mmap 本身没法支持异步读操作 IO,即无法使用 libaio 或者 io_uring 机制
其次,与 mmap 配套的 mlock 并没有真正避免页面淘汰的原语承诺。其原因是操作系统不可能完全信任用户态,每个进程能获得的资源总是有限的:如果全都锁了,OS 都顶不住
这两个细节放在一块可能会引起 IO stall,因为对于透明 page cache 来说,你随时会踩雷(再次用到被淘汰的页面,不得不走一遍 page fault),这对于抖动敏感的应用(不希望突然 block)不应该使用
并且这个不受控的 cache 维护问题没有足够好的解决办法,作者给出如下建议:
- 自己实现 page 使用情况的跟踪机制
- 开启独立的线程去处理 IO
- 针对你的 IO 特征,使用
madvise调优,也许管用
性能问题
mmap 最大的问题是透明页面导致的性能问题
在实验上,作者得出的结论是不适合应用于高吞吐的现代设备,从架构上找原因可能是 mmap 本身是在低带宽时代设计的,并没有考虑全面
在实现上,虽然前面提到的 2 点确实是优点,但是页面淘汰机制却成了瓶颈。具体分为 3 个部分:
- 页表的竞争
- 单线程的页面淘汰
- TLB shootdown
TLB shootdown 指的是 mmap 过程中,触发 page fault 后 CPU 本地的 TLB 会加入 PTE 映射,但是淘汰时可能需要让远程 TLB 失效,为了同步 TLB,需要各 CPU 见通过 IPI 中断去完成,而这需要花费数千的机器周期
在后续的 kernel 优化可能会解决掉前 2 个问题(作者使用的内核版本是 v5.11),但是第三个问题是需要从 CPU 架构去改进
注:我也从其它的资料中查了一些 overhead 占比,如图所示(而且是没进行页面淘汰的情况下):

落地问题
实际上 DB 厂商不会把 mmap 作为首要实现
如今 mmap 可能是个替代用的选项;也可能是以前用过,但现在移除掉了
END
这篇论文其实很短,一个散步的时间就看完了。虽然对于我比较关心的性能问题,作者也是飞快略过了,但也有点收获(我没想到是从 IO 以外去看待问题)
有空再仔细看下实验部分,也许能挖掘点其它信息(虽然粗看就是 mmap 完全贴着地板走)
总之先这样吧