粗略看了西半球最快内存分配器 mimalloc 的论文和源码,这里简单做点笔记。本文是论文阅读篇。
亮点
论文 Mimalloc: Free List Sharding in Action 提到 mimalloc 跑得快的设计要点有三处:
- 使用三种页级本地(完全无锁)链表并实现分片,提高局部性和避免竞争。
- 高度调优的快速路径,路径尽可能短且少分支。
- 可预测的周期性维护操作(temporal cadence),可以用于批量处理(比如延迟释放)。
这些策略使得 mimalloc 分别比高性能的 tcmalloc 和 jemalloc 还要快 7% 和 14%。
设计动机
mimalloc 当初是为了支持 Lean 和 Koka 语言的运行时而产生的,它们有这两种负载特征:
- 都是函数式编程语言,需要频繁分配短周期、小尺寸的对象(并且 jemalloc 在这里表现不佳)。
- 运行时使用引用计数来管理内存,需要提供延迟释放的特性来避免大型数据结构引起的停顿。
这也暗示了 mimalloc 在这种负载下可能有更好的性能表现。
链表分片
Allocation free list
论文指出许多分配器是基于 size-class(按大小划分)的方式来实现 single free list,这种做法并没有足够好的空间局部性。

比如上图 (A) 位于一整块的堆空间,在 free list 上新分配一个包含 3 个元素的链表 p 后如图 (B) 所示,这种支离破碎的现象并不罕见。
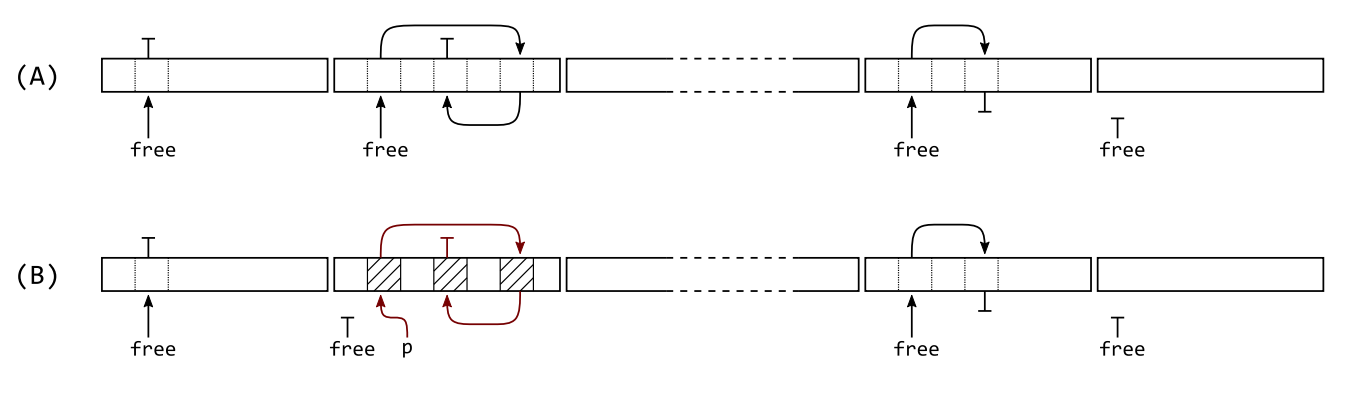
mimalloc 通过分片的方式解决这个问题。堆按 size-class 被划分为多个页,通常每个页的大小为 64KB。很显然使用分片后,局部性得到提升(见红线部分)。微软也基于 Lean 编译器做了基准测试,表示这种策略提高了 25% 的性能,主要是因为 L2 cache 命中率的提升。
Local free list
对于大型数据结构来说,free() 操作实际会引起递归嵌套的多次 free()。为了避免类似最坏情况,可以引入一个计数器,当 free() 达到一定次数后就把剩下的指针放入延迟链表(论文是基于引用计数的前提去讨论的,因此称为 deferred decrement list,但也说了这种情况不管是否引用计数都会存在)。
至于什么时候才对延迟链表进行 free(),那就是当内存资源紧张时:mimalloc 为上层提供一个 deferred_free() 回调,当 free list 为空的时候会被调用。而这种操作是在慢路径(generic path)中才存在的,仍保证了快路径的高效。这里的设计思路是任何麻烦事情都应放到慢路径。
那又有问题了,我该如何保证慢路径总会在某时刻被调用到?比如反复的在同一个页内分配释放,但恰好链表不为空,那不是完蛋了?mimalloc 针对这种情况保证了慢路径会在固定分配次数后必然调用。
为此 mimalloc 再次在每个页面切分一个 local free list。当我们分配时,会从常规 free list 分配对象,而释放时,对象会放回到 local free list。因此分配用的 free list 是肯定会在固定操作次数后变为空链表(所以是可预测的)。另外当 free list 为空时,则直接将 local free list 切换为 free list 使用,使得可以继续分配。这种情况仍不需要为快速路径付出任何代价。
Thread free list
mimalloc 中的页归属于线程局部的堆,其分配是本地完成的,因此无锁是理所当然的。但是,对于一个对象来说,任意线程都可以释放它。为了避免 free() 操作持锁,mimalloc 再一次为每页面切分 thread free list,并且把其他线程释放的对象都使用原子操作放到这个链表中。
同样的,在慢路径中也会收集 thread free list 并最后切换为 free list 使用。
这种操作尤其适合非对称的并发负载,也就是一部分线程主要负责分配,另一部分线程主要负责释放。
快速路径
论文没有单独的篇幅来介绍快速路径,这里简单体会一下它有多快:
void* malloc_in_page( page_t* page, size_t size ) {
block_t* block = page->free; // free list
if (block==NULL) return malloc_generic(size); // generic path
page->free = block->next;
page->used++;
return block;
}
分配流程并不使用碰撞指针,只需简单的寻址以及单个判断分支即可完成。
实现
Data structures
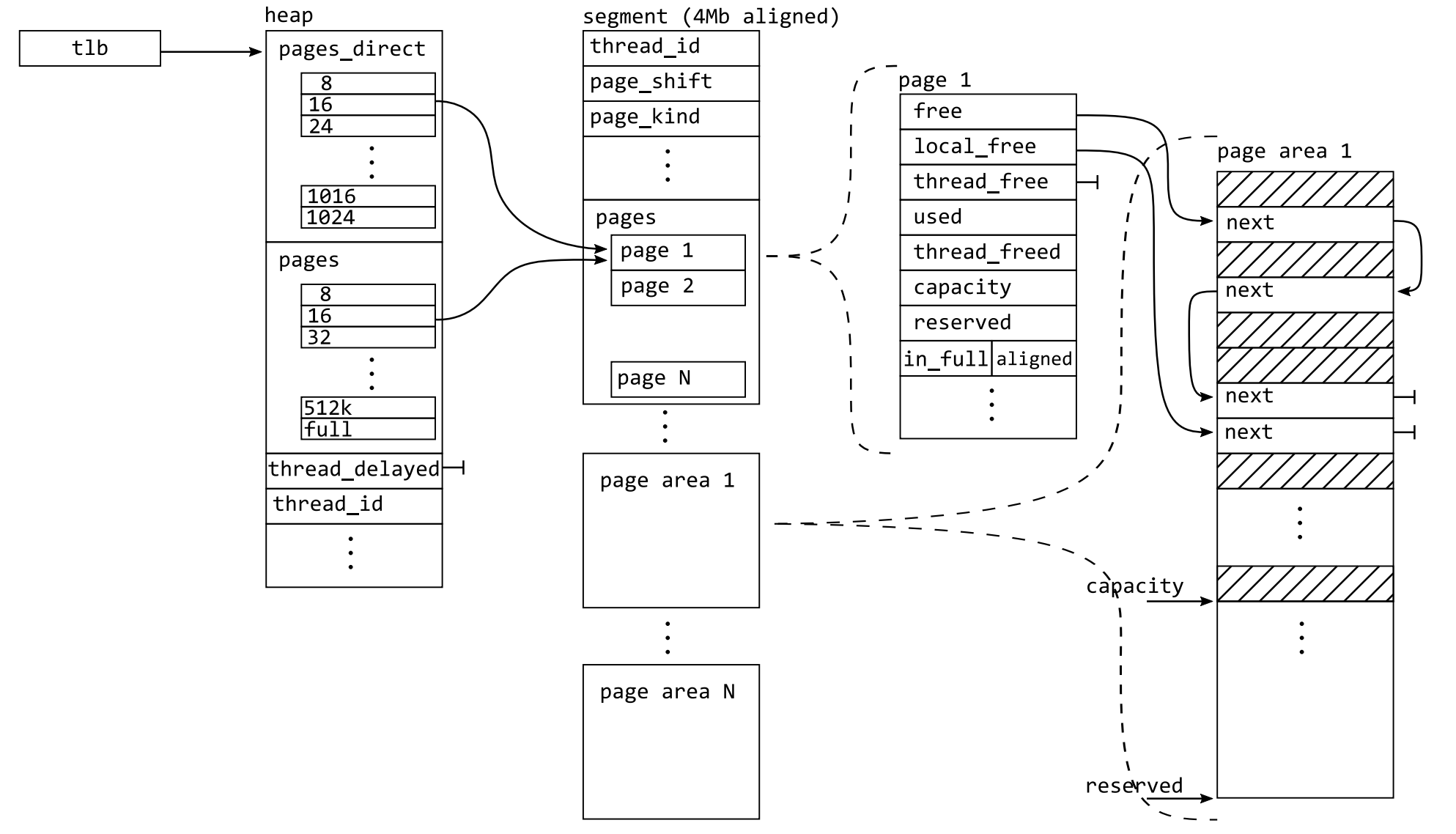
上图就是 mimalloc 设计的堆,通过 tlb(thread local data)寻址得到。而堆按照 size-class 计算下标索引可以得到页。
页和元数据都存放于段中。段的头部存放元数据,因此段中首个页面的大小实际要减去元数据大小。
一般来说,段的大小为 \(4MB\)。实际上 mimalloc 根据对象大小设计了三种页面/段的对应关系:
- small:小于等于 \(8KB\) 的对象使用,页面大小为 \(64KB\),段中有 64 个页面。
- large:小于等于 \(512KB\) 的对象使用,段中只有一个页面。
- huge:大于 \(512KB\) 的对象使用,段中只有一个页面,段的大小取决于对象大小。
对于 large 和 huge 仍然使用段的概念是为了保证代码的一致性,减少 special case。
malloc()
上面快速路径的代码展示了已定位到 page 的情况下的内存分配流程,这里补充一下 page 寻址。对于小对象(\(\le 1KB\))来说,可以通过 pages_direct 寻址:
void* malloc_small( size_t n ) { // 0 < n <= 1024
heap_t* heap = tlb;
page_t* page = heap->pages_direct[(n+7)>>3]; // divide up by 8
return malloc_in_page(page, n);
}
慢路径分配会在后面解释。
free()
与其他分配器相同,free(p) 需要获取 p 相关的元数据。也正是这个理由,mimalloc 将元数据放到堆的首部。由于堆是按照 \(4MB\) 对齐的,因此可以通过位运算得到元数据:
void free( void* p ) {
segment_t* segment = (segment_t*)((uintptr_t)p & ~(4*MB));
if (segment==NULL) return;
page_t* page = &segment->pages[(p - segment) >> segment->page_shift];
block_t* block = (block_t*)p;
if (thread_id() == segment->thread_id) { // local free
block->next = page->local_free;
page->local_free = block;
page->used--;
if (page->used - page->thread_freed == 0) page_free(page);
}
else { // non-local free
atomic_push( &page->thread_free, block );
atomic_incr( &page->thread_freed );
}
}
其中 page_shift 根据不同页面有不同大小:small page 为 \(16\)(位移得到 \(64KB\));large/huge page 为 \(22\)(位移得到 \(4MB\))。因此对于后者来说,index 永远是 0。在这种基于地址偏移量的释放算法中,p 并不需要记录大小信息。
后面主要的分支是判断是否本地数据。这里需要高效的 thread_id() 实现,而在大多数平台中,这个操作是足够快的:比如 Linux x86-64 实现仅需要获取 fs 寄存器。
正如前面所说的,p 可能会放回 local_free 或者 thread_free。对于 local free 的情况,还会判断页面所有对象已被释放的情况,这里会紧接着对页面执行释放。这种操作完全是可以省略掉的,就是说可以放在慢路径上再去处理,只是这样做会更加高效。
Generic allocation
通用分配流程即前面提到的慢路径,因为它通常是做一些更昂贵的操作。
void* malloc_generic( heap_t* heap, size_t size ) {
deferred_free();
foreach( page in heap->pages[size_class(size)] ) {
page_collect(page);
if (page->used - page->thread_freed == 0) {
page_free(page);
}
else if (page->free != NULL) {
return malloc(size);
}
}
.... // allocate a fresh page and malloc from there
}
void page_collect(page) {
page->free = page->local_free; // move the local free list
page->local_free = NULL;
... // move the thread free list atomically
}
简单来说,慢路径以 size-class 线性遍历 page list 中的页面,遍历的过程中顺手释放页面(与上面 free() 流程的 if 分支是相同的操作),直到找到任意可复用的对象就返回。实际的实现流程会复杂点,比如页面释放不一定是立刻执行的,可能会留存一些作为缓存;以及释放页面数是有限制的,避免整个函数延迟过高。并且也对 for-each 做了优化,如果找到了可用的页面,那么下一次的慢路径直接从这个页面开始遍历。
Full list
mimalloc 的核心算法已经介绍完了,也在大多数基准测试中表现不错,但仍需要在特殊场合改进:测试发现大量满页(full page)时会引起 30% 的性能下降,这种情况发生在大量长生命周期的大对象分配上。而满页导致性能下降的原因很直观,就是满页仍然留存在 page list 中,而慢路径 malloc() 是需要线性复杂度去遍历的。
一种朴素的解决方案是实现一个 full list:当页面分配已满时则将其放入到 full list 中,当任意对象释放时再放回 page list。这种做法能解决性能问题,但是使得线程安全的处理变得复杂。
所以 mimalloc 再次在堆上新增一个 thread delayed free list,里面存放的是非本地释放的对象。也就是说非本地的 free() 操作,会把对象原子地放入到 thread delayed free list 中,而在慢路径的分配过程中因为必然是本地操作的,因此可以把这些 delayed free 的对象都释放掉,并且非满页也可以从 full list 移动到常规 page list 中(前面提到,慢路径的调用是有周期性的)。
但前面非本地的 free() 操作也提过会放到 thread free list 中,这种情况该如何区分?mimalloc 使用 tagged pointer 的技巧,在 thread free list 指针的低 2 位上用了三种标记:
- NORMAL:一般情况,表示放到 thread free list。
- DELAYED:页面移动到 full list 时,打上该标记,表示非本地
free()要放到 delayed free list。 - DELAYING:临时标记,表示线程终止时堆仍然可用的特殊情况。
执行 delayed free 后,总会还原到 NORMAL 标记。
总结
goto #亮点;