前言
这篇 paper 的主要价值就是设计一个无敌的分布式 KV
注 1:对你没看错,是 memcache 而不是 memcached——memcache 指 facebook 设计的分布式缓存层服务,而它只是底层选用了 memcached 实现(理论上,换成别的完全 ok)
注 2:虽然 facebook 已经换了名字,但是文章仍然采用 facebook 的称谓
读多写少的系统
通常互联网服务大多为读多写少的场合,facebook 作为全球最大的社交网络也不例外
“全球最大”既包括当年论文发表时的时间点,也包括本文发表时的时间点
facebook 给出的数据是:读请求相比写高出 2 个数量级
具体地,每秒读请求为 billions 级别 (\(10^{10}\)),系统存储量级为\(10^{12}\)个条目
facebook 在这里隐含的意思是:memcache 的设计足以承担以上量级的服务
前面为什么说它是无敌的?如果要反驳,你首先要找到量级上打得过它的……
读写操作
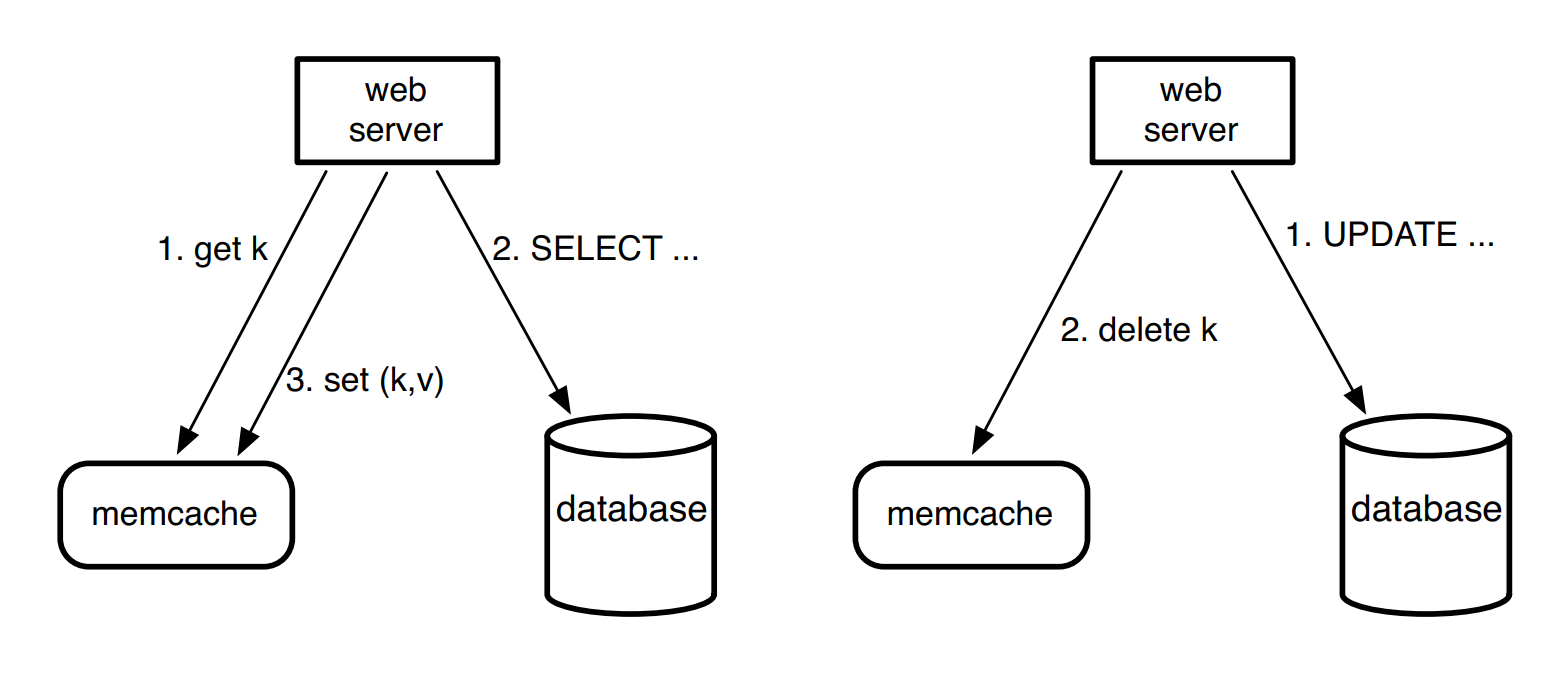
读操作:
- 查 cache
- 如未命中,查 DB
- 如走了第二步,接着 set kv
写操作:
- 更新 DB
- 删除对应 cache
写操作使用删除而非更新 cache 来满足幂等性
写操作之幂等支持
什么场合下需要幂等性?可能是在有任何异常情况下:
- 返回一个含糊不清的响应状态
- 很长一段时间没有响应
因为幂等性质,当发生异常时则允许直接重试而不必担心副作用。这个和超时机制搭配起来很不错!
非幂等应该也是可以的,但需要应用层进一步做校验,使用 token 等手段,可能不好处理
整体架构
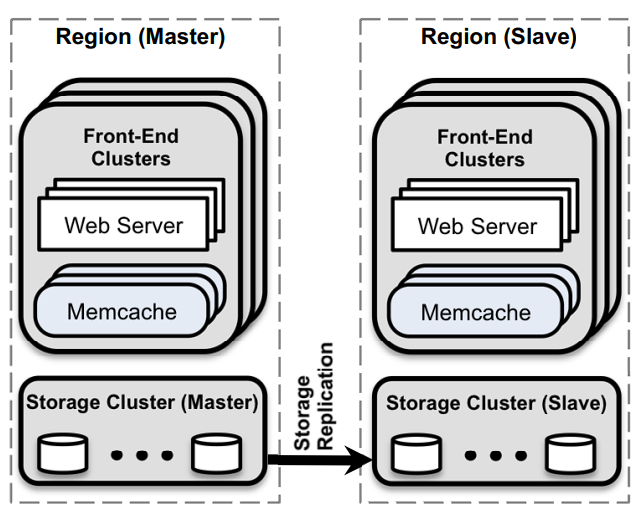
如图所示,一个 region 对应一个数据中心,单个 region 内有多个 cluster 的 replica
在部署规模上,单 cluster 对应\(10^3\)量级的 memcached server,其中的数据使用一致性哈希分布于各个 memcached 中
这种方式下如果某用户与单个 web server 通信请求服务,其单请求需要引起多个 memcached 通信。见后面“数据类型”和“延迟优化”章节
数据类型
这种应用场合下的数据类型是宽 fan-out 的,即放射状的读模式:用户表面上读一条数据(item),其实过程中涉及到读上百个数据
优化目标
先设定优化的范围:优化需要是能影响到用户的,而不考虑过于局部的优化
比如允许读稍微陈旧(不一致)的数据,只要能提高系统整体负载能力
并且把读到陈旧数据的概率作为一个调参参考(我没看懂?)
后续本文会从架构上分离,把优化过程分为 cluster 优化以及 region 优化
cluster 内的优化
优化预期
cluster 内的优化目标为:
- 减少 cache hit 时的延迟
- 减少 cache miss 时增加的系统负载
延迟优化
前面的“整体架构”中提到 web server 与 memcache 服务的通信方式,这很显然会造成 all-to-all communications
而 all-to-all 会造成两个问题:
- incast congestion
- 这个有点含糊,大概意思应该是数据短时间突发会造成网络拥塞
- 我觉得跟拥塞窗口的保守状态有关
- 单 server 的热点瓶颈问题
通过实现 replica 可以解决单点问题,还顺便做到容错,不过这需要花费内存利用率上的成本
facebook 的做法主要通过客户端的手段来减少延迟,手段分为:
- 请求优化
- 通信连接优化
(顺便一提)这个客户端的功能包括:
- 序列化
- 压缩
- 请求路由
- 错误处理
- 请求合并
请求优化
请求优化简而言之就是要减少网络上的 round trips 次数
优化手段主要是:
- parallel(并行化)
- batching(合并)
要实现这一目的可以把数据间的依赖调整为一个 DAG 图,由于并不存在环,因此可以并行发出请求
同时在必要时合并多个请求,经验值给出可以合并 24 个 key
通信连接优化
通信连接优化分为三个层面:
- client-server 通信
- 传输层连接
- 突发流量控制
在通信层面上
memcached server 间互不通信
facebook 希望把所有复杂实现下放到无状态的客户端
client 通过一个 mcrouter 的代理与 server 通信
即 web server 连接 client(proxy)即可,proxy 接口仍然保持和 memcached server 一致
这样避免了单个 web server 直连多个 memcached server
在传输层上
连接尝试尽可能通过使用 UDP 来减少 overhead,比如读请求
UDP 虽然不可靠,但是实验给出的数据是:即使处于服务高峰,也仅有 0.25% 的读请求被抛弃
注:这里并不是基于 UDP 重造可靠传输轮子,论文中最多只提到 UDP 上会用序列号标记顺序
如果不可靠请求被抛弃或者存在乱序行为,则是作为 client 端的错误,这样可以简化处理
比方说,get 失败了,则认为是应该走 cache miss 流程(但是事实上并不引起插入行为,只是复用 error handle 流程简化代码)
出于可靠性的考虑,set 和 delete 操作仍使用 TCP,因为 TCP 机制上保证了失败重试的机制,而不用基于 UDP 手写错误处理
在数据上,UDP 的引入使得请求整体延迟降低 20%
不过,即使使用 TCP 仍有优化的必要,因为 TCP 连接本身需要占用更多的内存资源(比如缓冲区),这里略过了
突发流量控制
上述是一些整体上的延迟降低方案
对于突发的网络拥塞问题,memcache 实现应用层面上的流量控制
实现上就是滑动窗口那一套,只是相比 TCP 不同在于来自同一个 web server 的请求会放入到同一个窗口(而不是维护单连接的窗口):当超出窗口范围时,主动拒绝响应,避免级联压垮 server
不过具体的实现算法并没有给出,毕竟这是玄学(
负载优化
我们不仅需要依靠 replica 和 sharding 来分担负载成本
还需要减少 load 次数从根本上解决负载问题
没有输入,那就没有负载,多么简单的道理!
但需要注意除了次数以外,即使数量很少的 cache miss 也可能引起高负载
lease
过期写入和瞬时高压
memcache 引入 lease 来解决两个问题:
- 过期写入(stale sets)
- 瞬时高压(thundering herds)
过期写入涉及到正确性,因为分布式下的请求是异步乱序的,可能一个 key 被更新后还会收到一个更加旧的写入请求
瞬时写入是指特定的一个 key 突然有大量的写和读请求,写请求会使得 cache 失效,每下一次写(使得上一次的写等同于失效)后的读都可能打穿 DB,均摊下来每次读请求都非常重量级
数据结构
lease 的具体数据结构为 64bit 的 token,每个 lease 绑定某一个 key
lease 的生成时机为发生 cache miss 时,由 memcached server 发出
处理过期写入
lease 可以用于判断当前的写请求(请求时携带 lease)对于 memcached 是否已经过期
如果已经过期,则直接拒绝已减少请求次数,并且保证了正确性
处理瞬时高压
对于瞬时高压问题,memcached server 通过控制 lease 的发放频率来缓解
原理是只有拥有 lease 的请求才有资格访问 DB 并写回到 cache
facebook 给出的经验值是每 10 秒发放一次 lease
在这种情况下,10s 内的下一次请求会陷入等待状态
注:也可以选择重试,因为当前处理等待是因为此前含有 lease 的请求尚未写回到 cache 中,短期少量的重试可以很快得到已写回的 cache 中的数据
facebook 实验表明这种策略使得 DB 请求从 17K/s 降低到 1.3K/s
补充
补充关于请求等待的进一步优化
前面说到的等待 10 秒,是在不期望读到陈旧数据的前提下
只要你接受轻微不一致数据,你可以选择直接返回(旧数据)而不必等待(最新的数据),因此并不会有性能问题
这里隐含的意思是 key-value 数据结构并不是一个 pair of key and value,而是一个大小至少为 2 的按时间顺序排序的 list,删除操作只不过是把数据标记为过期,添加操作是往头部插入数据
因此,对于一个请求失败的错误处理策略可以选择若干组合:
- 等待
- 重试
- 直接拿取旧值
pool
facebook 注意到不同的系统有不同的 workload,并且 memcache 是作为通用 cache 层,全部对接同一套 memcache 可能不合适
注:这种不同 workload 来自不同的数据访问形式、内存占用、QoS 要求
为了满足不同个性的 web server 需求,memcache 中把一个 cluster 的 memecached server 划分为不同的 pool
……这一部分懒得翻了,并不大感兴趣。往局部性原理靠就好了:
-
简单点说就是把一下 cache miss 成本比较小的放到 small pool 中,而成本高的则把相应的 pool 搞大一点
-
这些 pool 因为共享同一块内存(起码单机内是这样),因地制宜的 pool 大小可以相比通用 memcache 更好地控制 workload
另外还提到 pool 内进一步 replica,暂时没悟出大师怎么把 1 张 100 块变成 4 张 50RMB 的道理(我太菜了
failures
影响负载还有一个因素是故障处理。如果 memcache 挂了,那就得提放访问 DB 引起的高峰 workload(当然你也可以选择不可用而不是高可用,直接拒绝服务),还有进一步可能引发级联故障
存在 2 种不同类型的故障:
- 大规模的服务挂了
- 小范围内的主机无法访问,可能是个别的网络/服务器问题
大规模下线
如果整个 cluster 都大规模下线,需要必须立刻把 web 请求转发到其它 replica cluster,以最快速度移除当前 cluster 内对 memcache 的所有的 load
小范围停顿
对于 cluster 内小范围的不可用,则使用 gutter 机制来处理——gutter 指代的是 cluster 内预留的小部分平常并不主动使用的主机。实践中,facebook 把这“小部分”规划为 1%
小范围不可用需要自动修复,而修复是需要一段时间的(数据给出是分钟级别的停顿)。在这一段时间内的高可用(原来应该访问到不可用服务器的请求服务)将由 gutter 服务器(gutter pool)承担,直到 gutter pool 也无法提供服务才进一步直接访问 DB
比较特殊的是 gutter 中的 key 过期速度会相比普通 memcached 更快,并且限制上层的 load 速率,尽可能使用相对过期的数据,以避免进一步加剧故障,把可用服务限制到一定水平
更新:“key 过期”应该换一种说法,是处于故障状态时 key 容易快速过期(外部 workload 导致)。gutter 对这种现象的权衡做法是写入操作时并不 invalidate cache,因此数据层面的表现为更倾向于使用过期数据(进一步放宽一致性以提高可用性)
gutter 对比 rehash
facebook 顺便在这里对比了用剩余机器直接 rehash 的做法,分析认为小范围不可用有可能是部分 hot key 或者访问不均衡(non-uniform key access frequency)造成的,rehash 对这种做法并无帮助(hot 的还是 hot,non-uniform 的还是 non-uniform),而是倾向于用 gutter 削掉这部分异常流量,并且不把问题扩散到 cluster 内外的其它服务器,同时 gutter 是转移了请求直接冲入 DB 的风险
在 facebook 的实践中,这种做法消灭了高达 99% 的可见故障
可以说是用非常小数目的机器做了非常出色的故障处理策略
region 内的优化
前面我们(不是我,是 facebook)用了非常多的手段来优化了各个 cluster 内部的性能
但这还没完,现在聊更加庞大的 region
replica
region 是多个 cluster 的 replica 集合(见“整体架构”章节的图):
- 包含多个 frontend cluster(即 web + memcache)
- 包含一个 storage cluster(即 DB)
这里的“多”个 cluster 就是 replica 副本(图片堆叠部分)
注:frontend 是相对于 backend 的存储层而言
注:facebook 在原文中较前的章节提到,用户是按照 IP 地址来选取 replica 访问
为什么需要 replica
如果不考虑 replica,对于横向扩展,一种可行方式就是买更多的机器,把一个 cluster 做得更大
但是,这种横向扩展是容易到达瓶颈的:
- 用户量增大,单点 hot key 会变得更热
- all-to-all 交互,导致 incast congestion 随 cluster 增大而更加严重
因此,需要另一种思维去解决,即 replica——通过副本的形式做成多 cluster
region 级别的失效
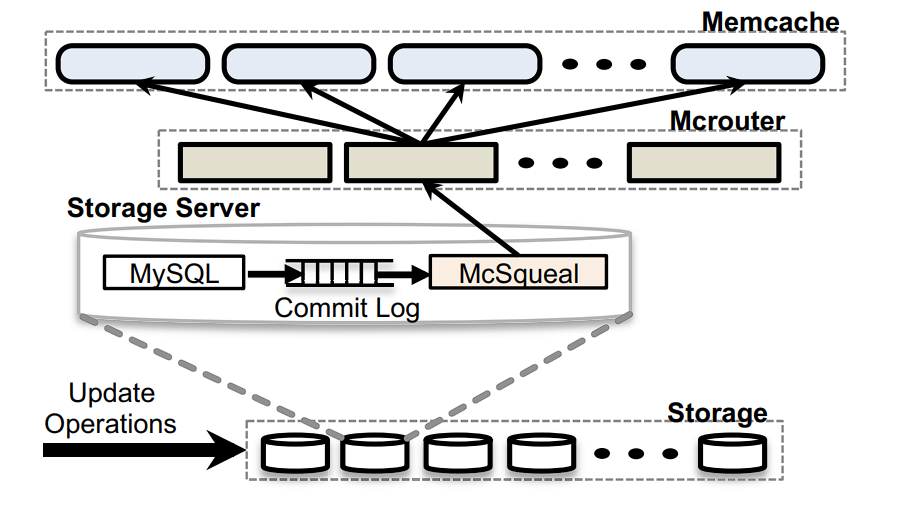
daemon
很显然,在这种架构设计下,storage cluster 具有权威的数据版本,用户的请求会使得数据按需从 DB 传递给(诸多)frontend cluster
既然产生了数据的副本,那么需要考虑如何让副本失效,以保证 frontend 和权威数据的一致性
facebook 的设计也是由 storage cluster 负责副本的失效。在 storage cluster 层,facebook 为每一个 DB 实例部署了 daemon 进程(McSqueal),每个 daemon 会监听 SQL 语句(commit log),如果一个事务有删除行为,则把删除操作广播到 frontend cluster
局部优化
除此以外,有一个利用局部性的优化:改动了数据的 web server 也会顺手让自己 cluster 中的 cache 失效。这样就满足了 read-after-write 特性,不仅提高了单用户的体验,还减少了本地 cache 的过期时间间隔
进一步减小包速率
虽然 daemon 可以直接和每一个 memcached server 通信,但是这样做的话,从 storage cluster 到 frontend cluster 的通信会很频繁
注意一个 memcache cluster 有很多很多的 memcached server!
于是有了进一步的优化:
- daemon 合并删除操作,使得网络包数减少
- daemon 只和每一个 frontend cluster 中的一个(或者一部分)memcached server,这些 server 运行着 mcrouter 实例(即前面提到的代理客户端),由 mcrouter 来广播到本地 cluster
region 级别的 pool
其实我们应该考虑是不是所有的 cluster 都需要做 replica 处理,如果能针对性优化,那将有助于提高整个 region 的内存利用率
比方说,对于一些使用率并不频繁的 key 保留一份就足够了,这些特殊的 cluster 被定义为 regional pool
(后略)
跨越 region!
多地数据中心
对于大厂来说,region 当然是有多个的
如字面意思,region 按地理区域划分,这样做有很多好处:
- 安全第一,避免自然灾害造成对数据的破坏
- 用户体验足够好,网络延迟得到物理性质的改善
- 为公司节约经济成本,多区域可以考虑电费更低廉的地方
一致性
facebook 设计的多 region 是 master-slave 形式:
- 只有一个 master region 是可以对 storage cluster 进行写入操作的
- 其它的 region 是只读的,即本质上是对 master 的 replica
- 它们的 master-slave 同步是依赖于 MySQL 的副本机制
这样做的好处是,任意 web server 都可以低时延访问本地 memcached 和 DB
而 facebook 写了很长一段话说我们最终一致性是 OK 的,这里不细说了。。。
master 的写操作
位于 master region 的写操作很好理解:
- frontend 收到写操作,下发到 storage,同时删除本地 cache
- storage 中的 daemon 解析 SQL,发给该 region 内的其它 frontend,让他们广播
- 同时 daemon 也从 master 广播到 non-master region
第二步就是“region 级别的失效”章节描述的内容
non-master 的写操作
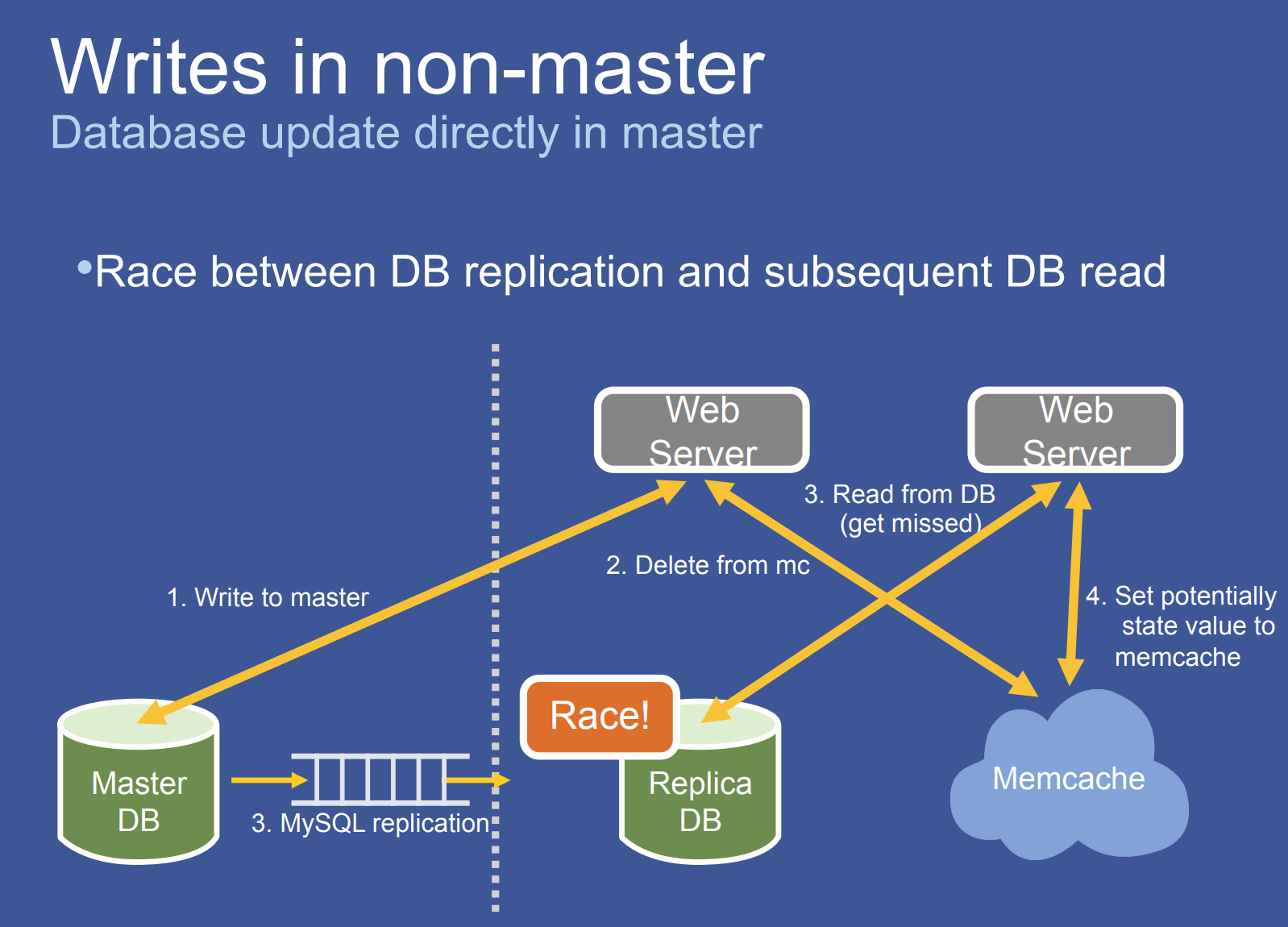
前面提到 non-master region 都是只读的,non-master 实际的写操作会转发到 master region
但这会造成潜在的竞争。如图所示,其竞争的关键点是 master 到 non-master 尚未更新完,non-master 的 frontend 又收到了读请求,于是读到了 stale data 且 cached
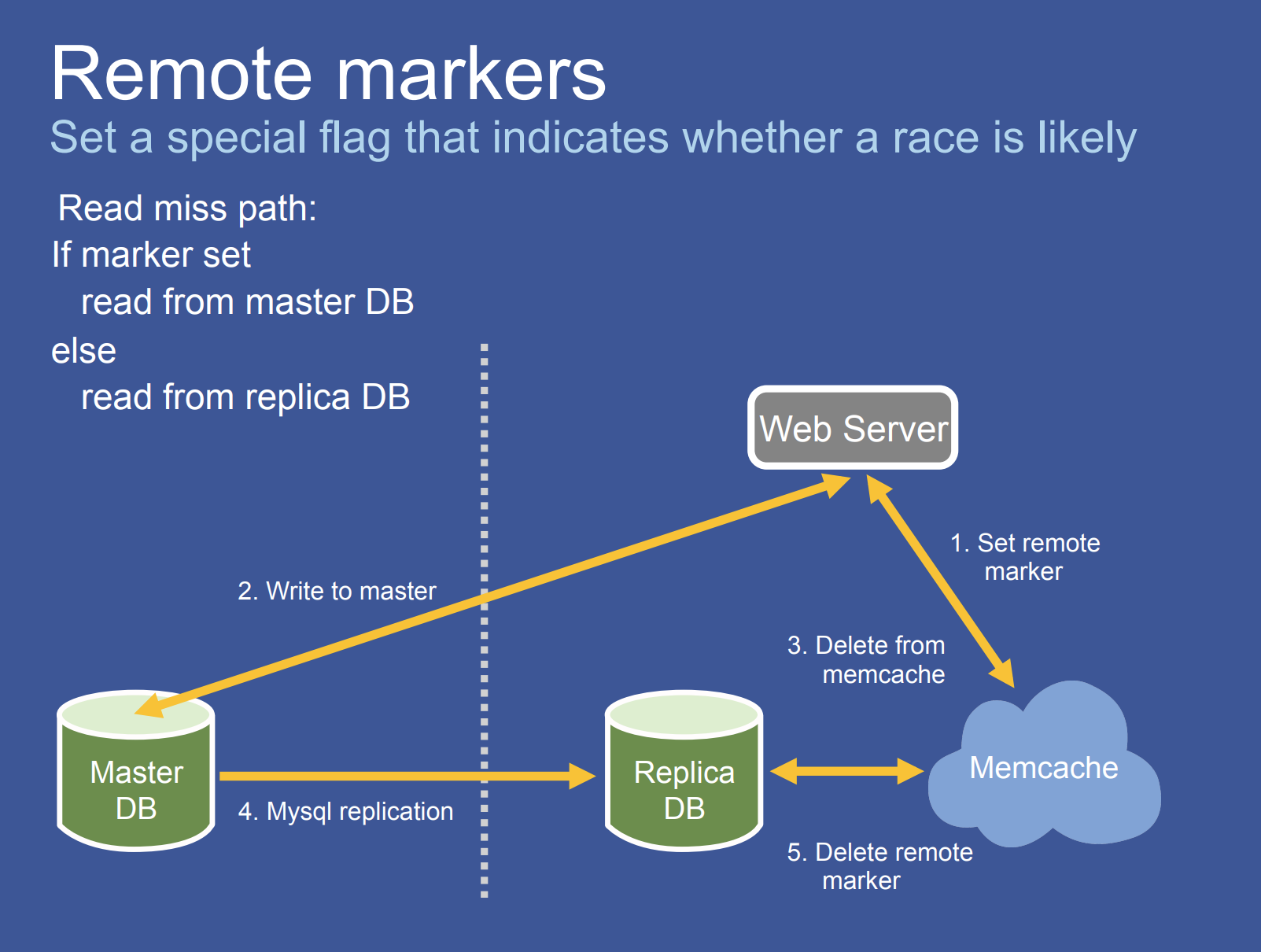
那么如何解决?facebook 引入了一个 remote marker 机制。简单地说就是写操作前先往 cache(对应的 key)打上该标记,那么在 cache miss 时(但是知道有这个 marker)会直接往 master region 的数据库获取数据
全篇完
原文仍有大量的数据可供参考,还有一些单机优化的讨论,感兴趣的可以去翻翻看