本文对早期的 浅读 perfbook:如果并行编程很难,那我能做点什么? 进行内容补充,进一步讨论弱序内存模型,提供更加丰富的代码模式以供理解。主要参考一篇极佳的论文 A Tutorial Introduction to the ARM and POWER Relaxed Memory Models,本文也是这篇论文的阅读笔记。
NOTES:
- 出于历史原因,论文视 Arm 为 non-MCA 系统。
- 本人不懂 POWER,只是论文标题是这样写的……
- 页表操作、自修改代码和外部共享域不在讨论范围内。
- 论文篇幅非常长,本文仅作自用笔记,注意极大幅度的精简会缺失一定的上下文信息。
基本概念
有三种内存模型的粗略分类:
- SC:任何写操作都会同时对所有其他线程可见;没有局部重排序。
- TSO:引入多副本原子性(Multi-Copy Atomicity);写缓冲可视为局部重排序行为。
- Arm/POWER:不具有多副本原子性(non-MCA);依赖以外,可视为全部乱序。
NOTES:
- 多副本原子性表明任何写操作都会同时对所有其他线程可见,一个线程可以在其自身的写操作对其他线程可见之前看到它们。
- 在其他文献中,可能会有 other- 前缀以区分这两种表现的耦合。
- TSO 具有代表性的用户是 SPARC 和 x86。
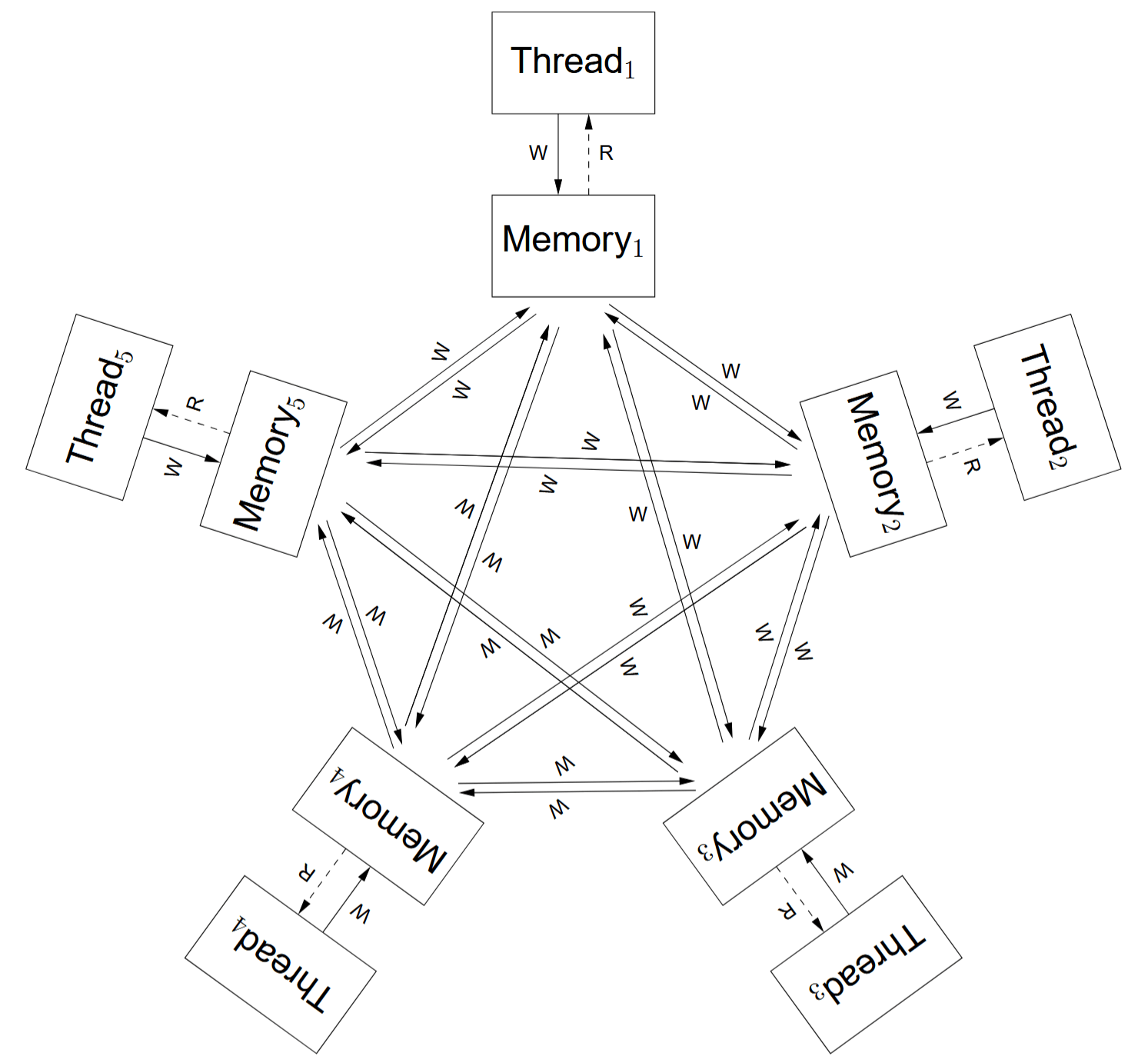
(图)想象的私有副本
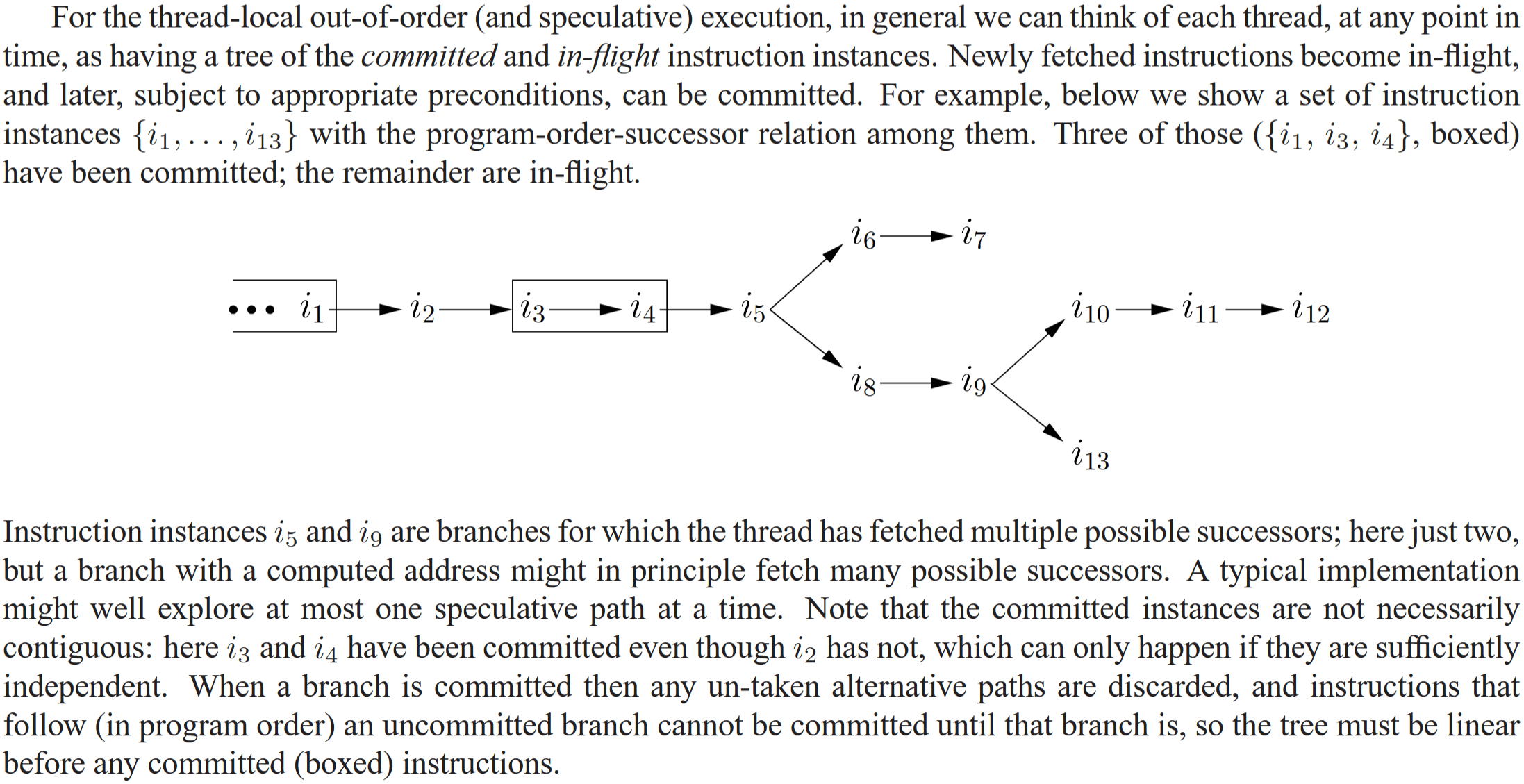
(图)想象的流水线
有两种给程序员用的心智模型可以简化分析:
- non-MCA:每线程持有私有变量副本。写操作会以任意顺序 传播 到其他线程的私有副本。
- 局部乱序或者推测:乱序执行、乱序 提交 的树形流水线;乱序提交需要满足一定的约束,比如未决分支和依赖。读指令具有推测性,只需确认地址(论文称之为 满足 )即可绑定值,后续依赖该值的指令可立刻执行且可在提交前撤回;写指令不可推测,需要确定地址和值;无论如何,提交后不可撤回。
NOTES:
- non-MCA 的屏障也具有传播特性。它也会提交到线程本地,之后可能向其他线程传播。
- 注意想象和现实的差距。现实硬件是采用乱序执行、顺序提交的设计。尽管论文没交代背景,它的想象依据应该是简化了写缓冲等相关细节,因此改用为乱序提交的说法。
有两种原子性的介绍(仅为区分多副本原子性的原子名词歧义):
- 访问原子性:表明一条指令的单次内存访问行为,值不可分割。又称为单副本原子性。
- 指令原子性:表明一条指令存在多次内存访问行为,时间上不可分割。
NOTES:
- 具有访问原子性的指令一般是要求满足合适大小和对齐。
- 具有指令原子性的指令可能有类似 LOCK;INC 的写法。
基本概念应该就这些了,超简单的。现在就来看具体场景吧!
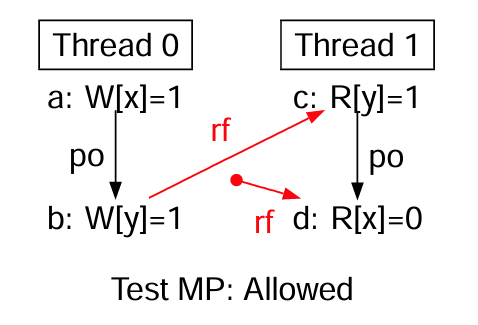
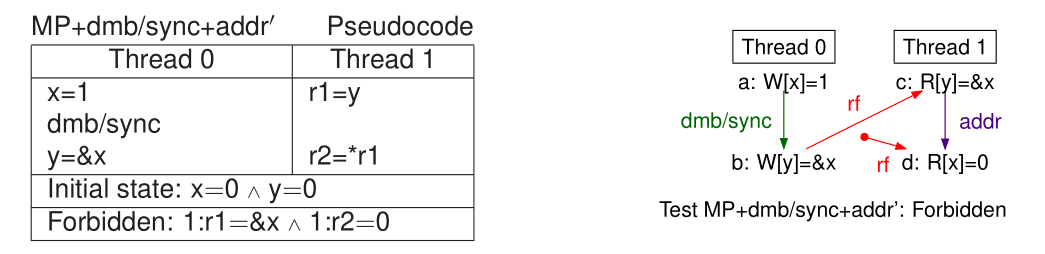
MP 测试
MP-loop 伪代码
线程 0 线程 1
x=1 // 写数据 while (y==0) {} // 忙等待标志
y=1 // 写标志 r2=x // 读数据
初始状态: x=0 ∧ y=0
禁止?: 线程 1 寄存器 r2 = 0
MP(Message Passing)是一种经典的代码模式。也就是在其他领域所常见的发布-订阅模式。它可以展示弱序模型与 TSO/SC 的不同。
补充一些关系名词,直接从先前的 perfbook 笔记拿过来了:
- po:表示 program order 关系,即线程内的指令顺序。
- rf:表示 read-from 关系,同一个变量的写操作指向读操作,操作之间具有先后关系,也就是读到指定的写提供的数值。简单点可理解为 exists 子句所指定的范围(没指定就由程序枚举状态)。
MP 失败(allowed)的原因可能有三:
- 线程 0 的写操作针对不同内存位置,允许乱序提交。
- 线程 0 的写操作允许乱序传播到线程 1。
- 线程 1 的读操作被满足,允许乱序绑定对应的值。
Data Memory Barrier (DMB) prevents reordering of data accesses instructions across the DMB instruction. Depending on the barrier type, certain data accesses, that is, loads or stores, but not instruction fetches, performed by this processor before the DMB, are visible to all other masters within the specified shareability domain before certain other data accesses after the DMB.
来源:Arm 官方文档
The dmb/sync barriers are potentially expensive, but satisfy the property that if inserted between every pair of memory accesses, they restore sequentially consistent behaviour. Looking at the four cases of a pair of a read or write before and after a barrier in more detail, we have:
- RR For two reads separated by a dmb/sync, the barrier will ensure that they are satisfied in program order, and also will ensure that they are committed in program order.
- RW For a read before a write, separated by a dmb/sync, the barrier will ensure that the read is satisfied (and also committed) before the write can be committed, and hence before the write can be propagated and thereby become visible to any other thread.
- WW For a write before a write, separated by a dmb/sync, the barrier will ensure that the first write is committed and has propagated to all other threads before the second write is committed, and hence before the second write can propagate to any other thread.
- WR For a write before a read, separated by a dmb/sync, the barrier will ensure that the write is committed and has propagated to all other threads before the read is satisfied.
来源:本论文。 需要注意这里的描述(satisfied/commited/propagated)仅面向前面所说的心智模型。
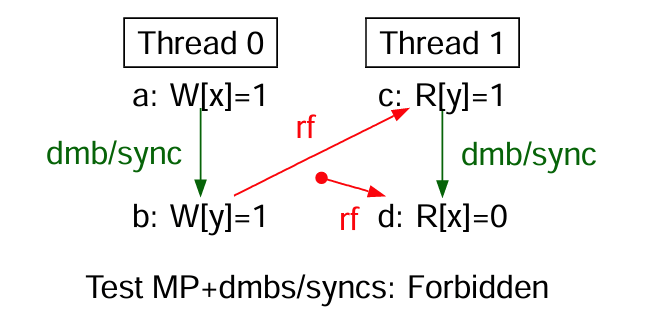 使用 DMB 提供屏障
使用 DMB 提供屏障
至于解决方案,Arm 可以直接使用 DMB 指令(Data Memory Barrier)提供屏障以保证 MP 成功,但这是过强的保证,实际可以挑选更加宽松的屏障以避免性能下降。
On POWER, there is a ‘lightweight sync’ lwsync instruction, which is weaker and potentially faster than the the ‘heavyweight sync’ or sync instruction, and for this message-passing example the lwsync suffices, on both the writer and reader side of the test. Looking again at the four cases above:
- RR For two reads separated by an lwsync, just like sync, the barrier will ensure that they are satisfied in program order, and also will ensure that they are committed in program order.
- RW For a read before a write, separated by a lwsync, just like sync, the barrier will ensure that the read is satisfied (and also committed) before the write can be committed, and hence before the write can be propagated and thereby become visible to any other thread.
- WW For a write before a write, separated by a lwsync, the barrier will ensure that for any particular other thread, the first write propagates to that thread before the second does.
- WR For a write before a read, separated by a lwsync, the barrier will ensure that the write is committed before the read is satisfied, but lets the read be satisfied before the write has been propagated to any other thread.
POWER 面临同样的问题,sync 指令过强,所以提供了 lwsync 指令(lightweight sync)。就观察者的角度来看,除了 WR(就是 store-load 顺序),其他均可适用。
论文提到 Arm 缺失与 lwsync 等价的指令,但这应该是历史原因。总之 DMB 指令还可以通过指定可选的访问类型(type of access,包含域和顺序两种参数)来变得更加宽松。
NOTES:
- 前面提到的 DMB 默认选项是 full system 域和 any-any 顺序。注意 Armv8 后是要显式声明的。
- 论文说的 Arm 没有类似 lwsync 的指令,应该指的是 Armv7 缺少单独的 load-load 顺序和 load-store 顺序的屏障。即使是 Armv8/Armv9,也没有单独一条指令能完全等价于 lwsync。
依赖
There are no dependencies from writes (to either reads or writes).
可以使用 依赖 以强制顺序。依赖由至少两个访问操作/事件构成,第一个访问操作必然是读操作。
本文范围内会生造三个名词:从读(from read)、到写(to write)和到读(to read)。从……到……是一个程序顺序关系(po)。尽管不像是中文,但这可以免去繁琐的描述。
地址依赖
 地址依赖
地址依赖
地址依赖:从读得到的值,被用于计算到读和到写对应的内存地址。上例是一个从读到读的测试(见线程 1),仅是将此前 MP 测试的 b 操作从写入 1 改为写入 x(的地址),便能在 c 和 d 两个事件构成地址依赖,从而提供合适的屏障强度。
Thread 0 Thread 1
x=1 r1=y
dmb/sync r3=(r1 xor r1) // 数据流链可以从一个寄存器捣到另一个寄存器
y=1 r2=*(&x + r3) // 等价于 R[x],但是有 addr 依赖
Forbidden: 1:r1=1 ∧ 1:r2=0
依赖可以是人为设计的(artificial)。论文用词有点抽象,总之是数据流中有被依赖的地址用于计算过程即可,上述 xor 例子的效果可以等价于此前的从读到写的 MP 测试,但是具有合适的屏障。
NOTES:
- 地址依赖使得到读满足必须晚于从读满足。
- 地址依赖使得到写执行必须晚于从读满足(因为必须得知地址)。
- MP 模式中,数据是允许多字大小的。对应于例子中的 x 内存位置。
控制依赖
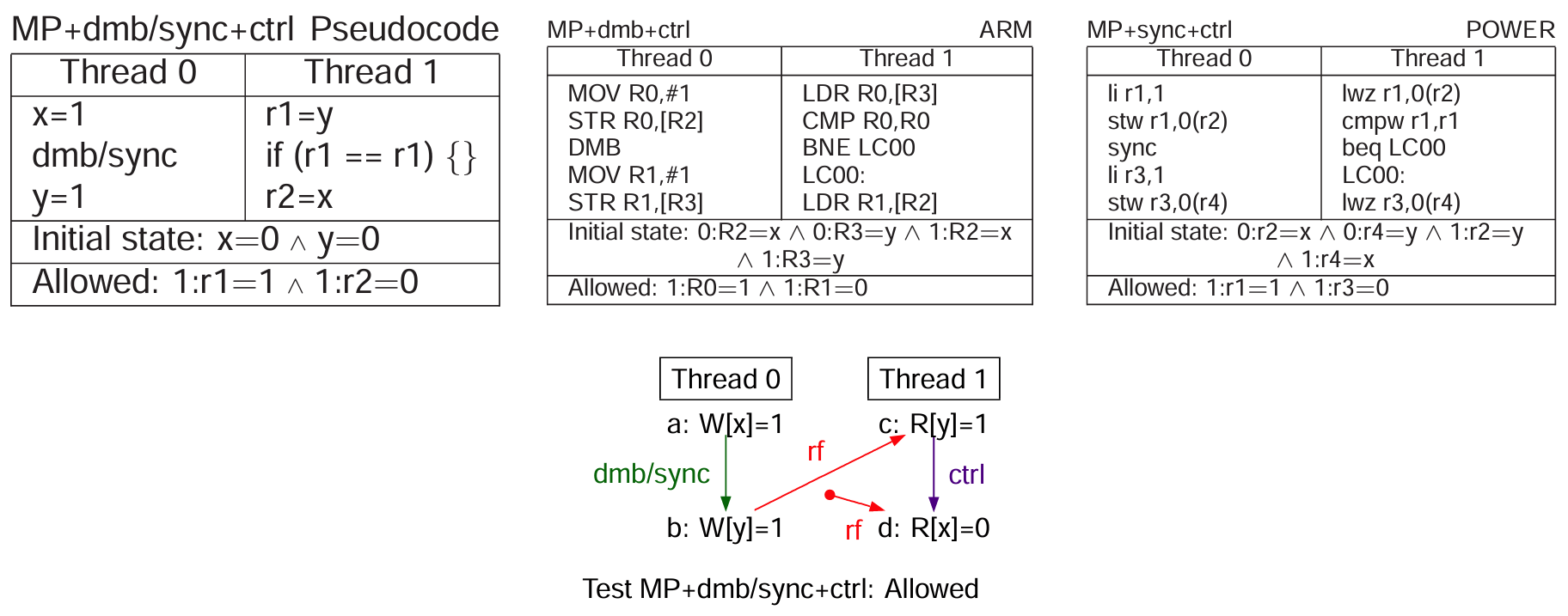
控制依赖:从读得到的值,被用于计算到读和到写(程序顺序)前的分支。省流版总结是,到读不具有屏障效果,到写有。
继续省流,为了给控制依赖场景下的从读到读提供屏障,可以添加 ISB 指令(Instruction Synchronization Barrier)。不过 Arm 文档并没有直接指出这种使用方法。而且这都比 DMB 严格多了……感兴趣的读者可以去琢磨 4.3 小节。
数据依赖
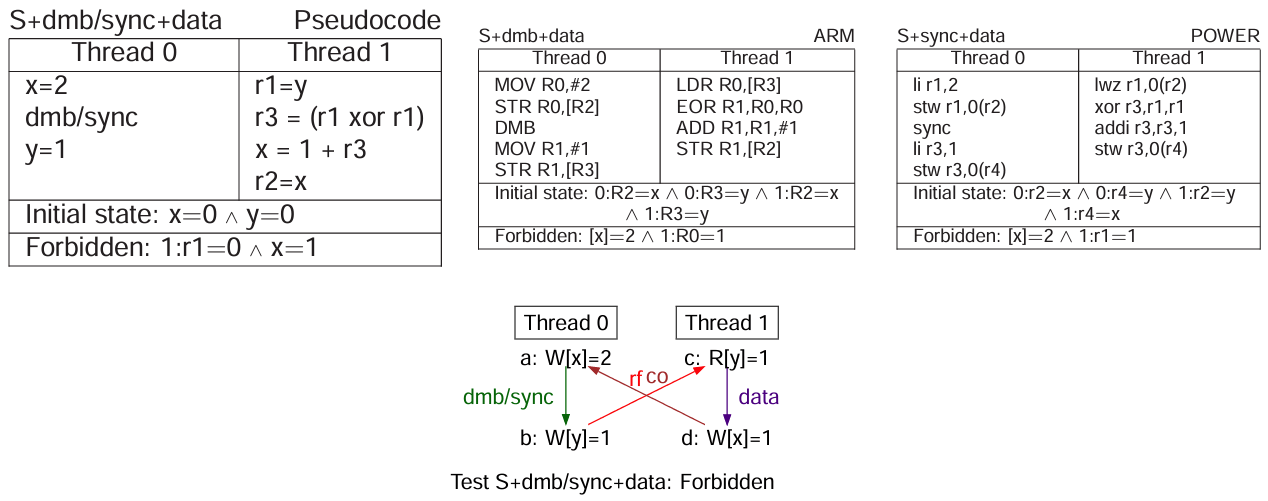
数据依赖:从读得到的值,被用于到写的写入。简单来说就是用于右手边的值。
句法依赖问题
很显然,论文是完全基于硬件行为的,不会考虑编译器。但还是要指出不太显然的 句法依赖(syntactic dependency)问题。
// 基于 Linux 内核提供的 ONCE 原语(因为我抄的内核文档)
// 例一:表面的数据依赖
r1 = READ_ONCE(x);
WRITE_ONCE(y, r1 * 0);
// 例二:表面的地址依赖
int a[1];
int i;
r1 = READ_ONCE(i);
r2 = READ_ONCE(a[r1]);
句法依赖指的是不符合 语义依赖(semantic dependency,即上面提到的各种依赖),由编译器造成的伪依赖场景。例一本意是一个数据依赖测试,尽管 ONCE 保证 r1 会被加载,编译器仍有可能会将 r1 * 0 变换为 0,从而去掉了语义层面的依赖;例二的编译器更是可以假定 a[r1] 只有 a[0] 的可能性,也就是说你的数据流链可能不存在 r1,不足以构成真实的地址依赖关系。
句法依赖和处理器的内存一致性模型没有关联,只是在这里提一下,读者感兴趣可以翻阅内核文档。
累积性
前面的依赖可以为 Arm 处理器提供比 DMB 指令严格更弱的屏障效果。对比之下,依赖只具有线程本地的效果(thread-local effects),缺失 DMB 指令具有的一种称为 累积性(cumulativity)的性质。如果是 POWER 处理器,那么对应的依赖则缺失 sync/lwsync 指令的累积性的性质。
When a processor (P1) executes a Synchronize or eieio instruction a memory barrier is created, which orders applicable storage accesses pairwise, as follows. Let A be a set of storage accesses that includes all storage accesses asso ciated with instructions preceding the barrier creating instruction, and let B be a set of storage accesses that includes all storage accesses asso ciated with instructions following the barrier creating instruction. For each applicable pair ai,bj of storage accesses such that ai is in A and bj is in B, the memory barrier ensures that ai will be performed with respect to any processor or mechanism, to the extent required by the associ ated Memory Coherence Required attributes, before bj is performed with respect to that processor or mechanism.
The ordering done by a memory barrier is said to be “cumulative” if it also orders storage accesses that are performed by processors and mech anisms other than P1, as follows.
- A includes all applicable storage accesses by any such processor or mechanism that have been performed with respect to P1 before the memory barrier is created.
- B includes all applicable storage accesses by any such processor or mechanism that are performed after a Load instruction executed by that processor or mechanism has returned the value stored by a store that is in B.
论文并没有提供累积性的定义,但是可以查阅 PowerPC Book 2。需要注意这个手册的描述非常抽象,并且 applicable 和 performed 是有严格定义的……
简单来说,累积性提供 因果 的直觉,解决部分的 传播 问题。更加详细但是仍然感性的描述是:
- 一个指令可以提供累积性屏障,为执行该指令的本地处理器以及(本地处理器作为观察者)观察到的其他处理器的访问操作进行排序。
- 根据定义,按照程序顺序,在其屏障之上的访问操作归为 集合 A,在其屏障之下的归为 集合 B。
- 如果在集合 A 中,本地处理器的读操作已经观察到外部处理器的写操作已传播的值,那么可以钦定该外部处理器此前的访问顺序也在集合 A 的范围内;
- 如果在集合 B 中,本地处理器执行且传播了写操作,并且被外部处理器的读操作观察到对应的值,那么可以钦定该外部处理器此后的访问顺序也在集合 B 的范围内。
- 这种性质还可以细分,关于集合 A 的描述称为 A-累积性,集合 B 的描述称为 B-累积性。
- 累积性强制了递归的执行顺序,因为集合 B 会递归地增长,关系也会产生传递。
其实累积性和语言标准内存模型的 synchronizes-with 很像,但是前者只需要单个显式栅栏,后者通常需要一对特定的访问操作来描述。
NOTE: synchronizes-with 关系正是基于 lwsync 的累积性实现的。详见 N2745。
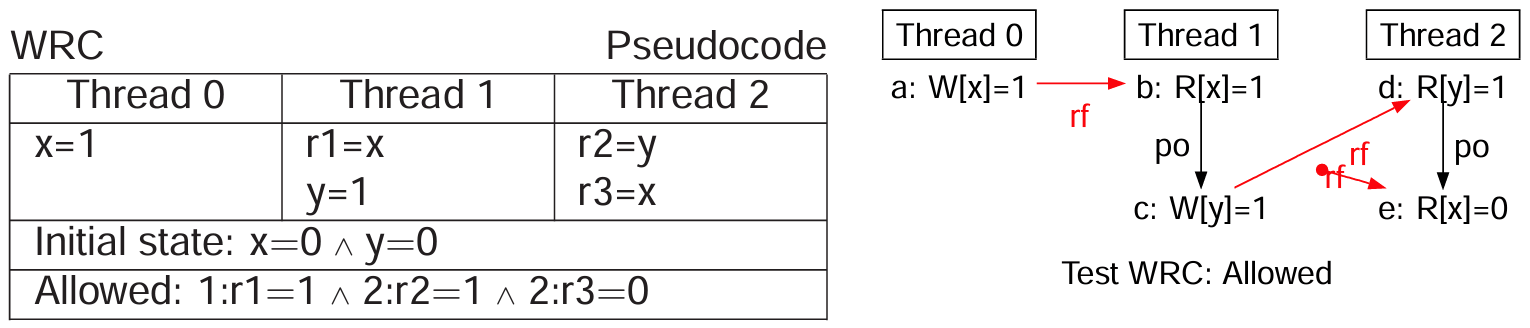
WRC 测试
WRC-LOOP
Thread 0 Thread 1 Thread 2
x=1 while(x==0){} while(y==0){}
y=1 r3=x
Forbidden?:2:r3=0
论文第五章提供超过两线程的 MP 测试变体:将原线程 0 的写标志操作单独分离到另一个线程 1 中。这个变体测试会暴露出 non-MCA 系统的传播问题。
 将前面的循环化简
将前面的循环化简
 进一步的,添加依赖
进一步的,添加依赖
该测试即使添加人为设计的依赖,也是测试失败的。这是因为依赖只能强制非递归的执行顺序,不提供累积性。
We call this example Write-to-Read Causality (WRC) because a write of a new value by a thread followed by a read of the same value by another thread is used to establish a causal connection between the threads. Most programmers agree that this causality should be respected……略
NOTE: 该测试也称为写到读因果性(WRC)测试。前面一章也提到,就是符合开发者直觉的意思。
 使用 DMB 提供累积性
使用 DMB 提供累积性
Arm 处理器可以使用 DMB 指令以提供累积性。按照前面的论述,Thread-1:DMB 的累积性屏障划分了明确的 A={a,b}, B={c,d,e} 集合,从而确保观察顺序总是 A -> B。
NOTES:
- 注意集合是无序的。
- 论文还提供了一个称为 ISA2 的测试,都差不多意思。至于名字的含义,我猜测作者是从 IBM 那本 ISA 手册抄录的示例,然后手册里面总共只有 2 个相关示例,所以……
SB 测试
SB 测试(Store Buffering)用于测试 store-load 顺序,这是 TSO 唯一允许的乱序行为。SB 测试的应用场景是 Dekker 互斥算法 实现。
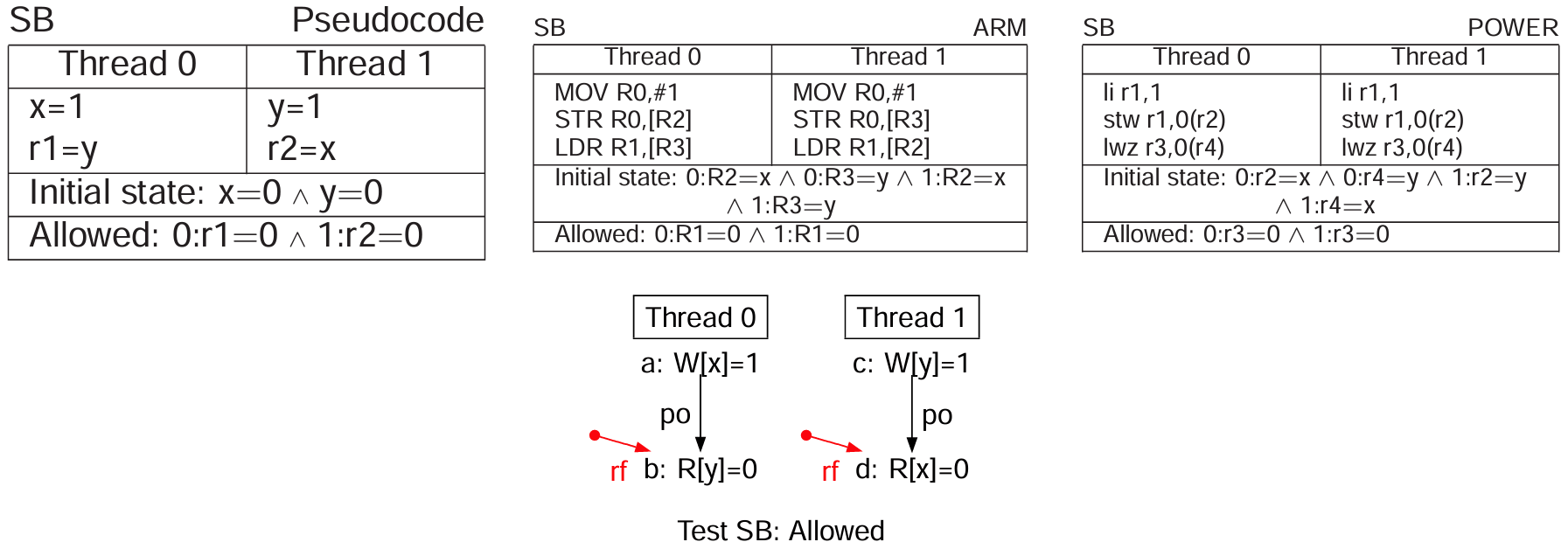
不使用任何屏障自然是乱序的,因此测试失败。
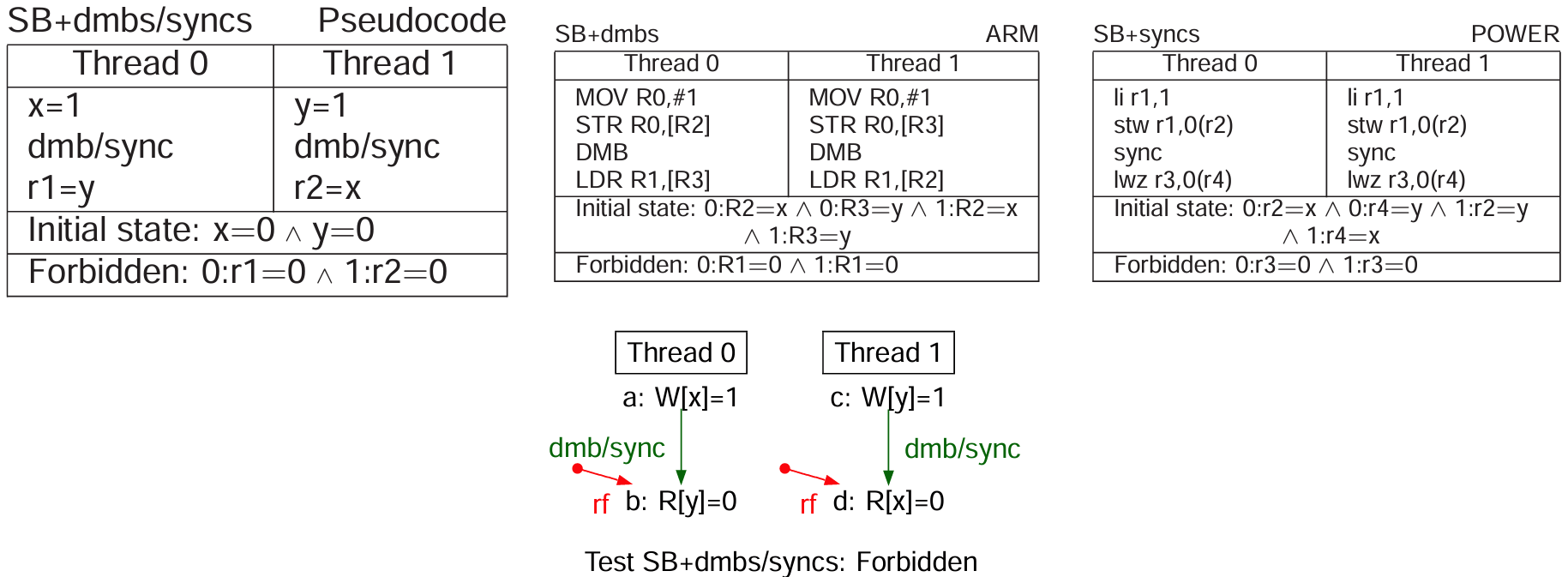
使用 DMB 或者 sync 指令可以解决该问题。需要注意基本的顺序问题,前面章节提到 lwsync 指令的屏障强度,它是不包含 store-load 顺序的,因此在本测试中并不适用。另外,DMB 指令不管是 ST 还是 LD 选项都没有单独的 store-load 顺序保证,这意味着至少需要用 any-any 顺序。另外是关于传播性质,前面已指出 DMB 或者 sync 指令确保程序顺序更早的写必须在读被满足之前传播到所有线程。
IRIW 和 RWC 测试

SB 测试可以扩展到更多线程。IRIW 测试(Independent Reads of Independent Writes)将 SB 测试的 x/y 的写操作分离到独立的两个线程,并且读操作也分离到独立的两个线程。
即使是进一步使用依赖(图略)控制线程 1 和线程 3 的顺序,也会同样得出线程 1 观察到 {x=1, y=0} 和线程 3 观察到 {x=0, y=1} 的结论。这说明写操作不仅会传播,而且传播的速率并不一致。

同样的方法,在读线程使用 DMB 指令即可解决。这里使用的是传播的性质。
NOTES:
- 累积性在这里是不足以解决问题的。按照前面的论述,想要构造可以递归/传递的集合 B,至少要有写操作在初始的集合 B,很显然读线程在这里没有写操作。
- 前面提到的传播性质,个人觉得可以直接描述为 恢复 SC。
有意思的是,作者提出非常务实的观点:IRIW 这种模式就没在现实世界中遇到过……
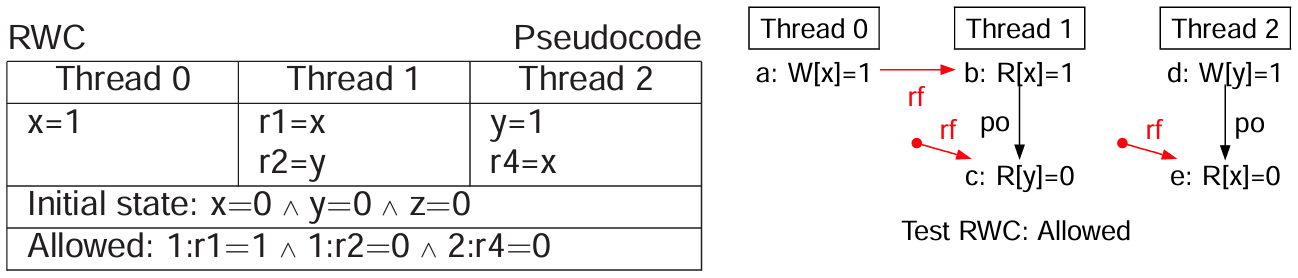
读到写因果性(RWC)测试是只分离一个 SB-写 的模式,同样需要两个 DMB 指令。
LB 测试
LB
Thread 0 Thread 1
r1=x r2=y
y=1 x=1
Allowed: r1=1∧r2=1
LB 测试(Load Buffering)用于测试 load-store 顺序。也就是说和 SB 测试恰好相反。
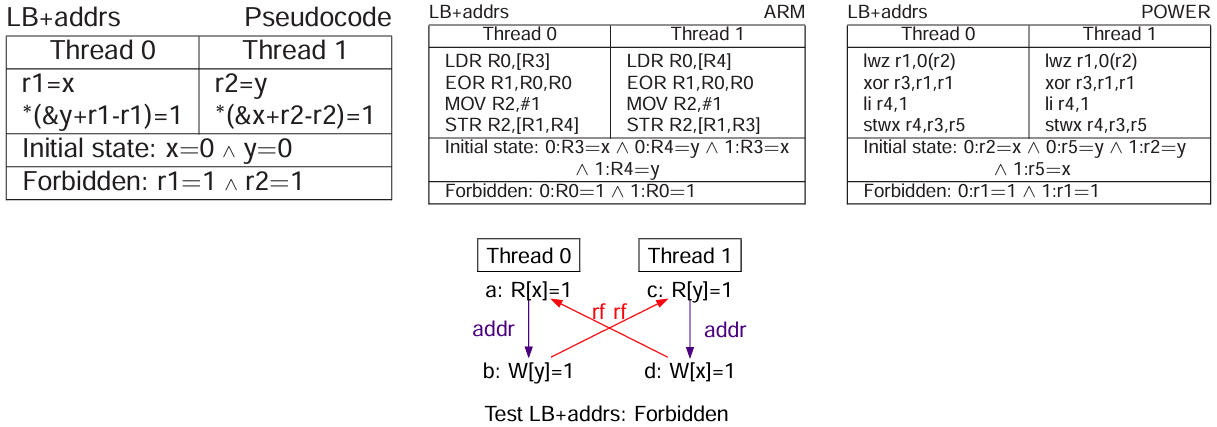
这个很简单,依赖、DMB、sync 或 lwsync 均可。上图为使用依赖的场景。
NOTE: 作者提到 LB 现象在 Arm 可复现,但是 POWER 意外地观察不到。
缓存一致性
缓存一致性是非常符合开发者直觉的,简单来说就是:对于单一内存位置,所有的处理器/线程都认同共享的写入操作视图。
至于「认同」的四条基本规则(CoRR、CoWW、CoRW、CoWR),直接看 C++ 内存模型的 modification order 描述吧,和硬件内存模型基本一个意思。
剩余 TODO
大方向的规则/模式基本就这些了,作者在第十章还加了一些非常细节的「微妙」测试,以后再看吧。
标记一些我感兴趣的:
- PPO 关系。
- LR/SC 测试:原文称为 Load-reserve/Store-conditional,其实和 LL/SC 一个意思。
- Peterson 分析。
图文无关
查资料时找到了多年前的高清迷因,分享一下,图文无关。
