本文简单梳理 Linux 内核 ftrace 子系统的实现思路,不算深入。背景是我在搜集其他资料时顺手下载了 ftrace 作者 Steven Rostedt 多年前的演讲稿,仅浏览数页,却像是经历了一场绝佳的 porn(没开玩笑,示意图画得很好,也很有启发)。惊叹过后又另外参考一些资料,整理得出这篇笔记。
免责声明:个人水平有限,演讲稿的内容不一定搞明白,如有错误还请指出。
TL;DR
ftrace 就是代码插桩。
代码插桩:gcc -pg
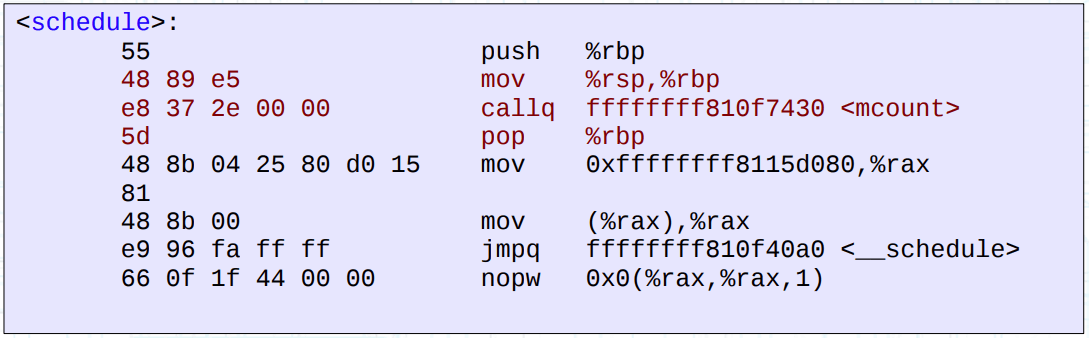
ftrace 最初使用 gcc -pg 的编译器选项(gcc profiler 特性),在编译阶段为每一个内核函数(非内联、非黑名单)的入口处插入了 call mcount 的指令,而 mcount() 则是一个函数,一般作为跳板(trampoline)去完成剖析工作。
NOTE: 使用了 -pg 编译得到的用户态程序是通过调用 mcount() 跳板而生成 gmon.out,再交给 gprof 工具去分析;但是内核只是使用了插入指令的特性,而 mcount() 被替换为内核内部的实现。
NOTE2: mcount@GLIBC 可以是一个弱符号,可能取决于体系结构等细节(粗略翻了文档)。
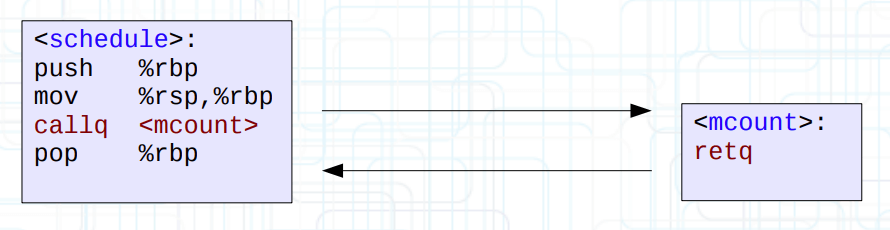
但是这里使用的是 retq 跳板,不断地 call 回弹会带来不菲的开销。Steven 指出这会使得系统整体性能下降 13%,而内核迄今没有为一个少数人使用的特性做出如此牺牲。这显然也不能用于生产环境,需要进一步优化。
优化 nop:链接魔法
优化的方式是直接把指令本身替换为 nop,这对现代 CPU 来说带来的负面影响已经微乎其微。为了做到这种事情,需要使用一种名为 recordmcount 的链接魔法。
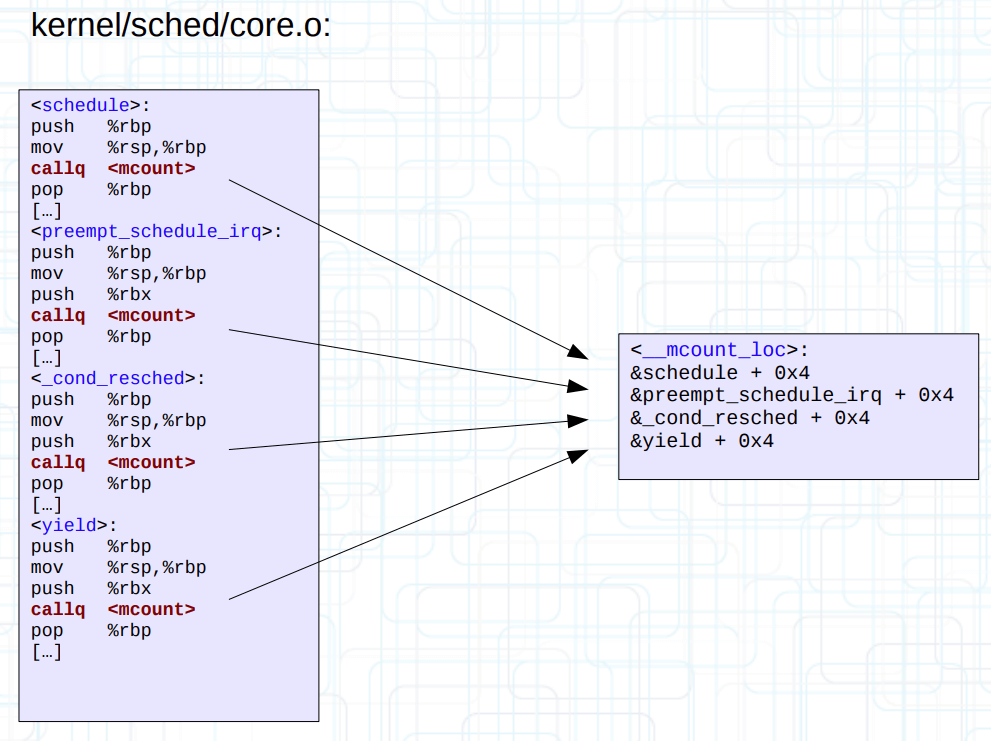
内核首先使用 scripts/recordmcount.c 工具,改变每一个 .o 目标文件的布局。具体来说是单个文件内读取所有 mcount 的偏移量,并写入到单独的 __mcount_loc 输入节(ELF input section)。
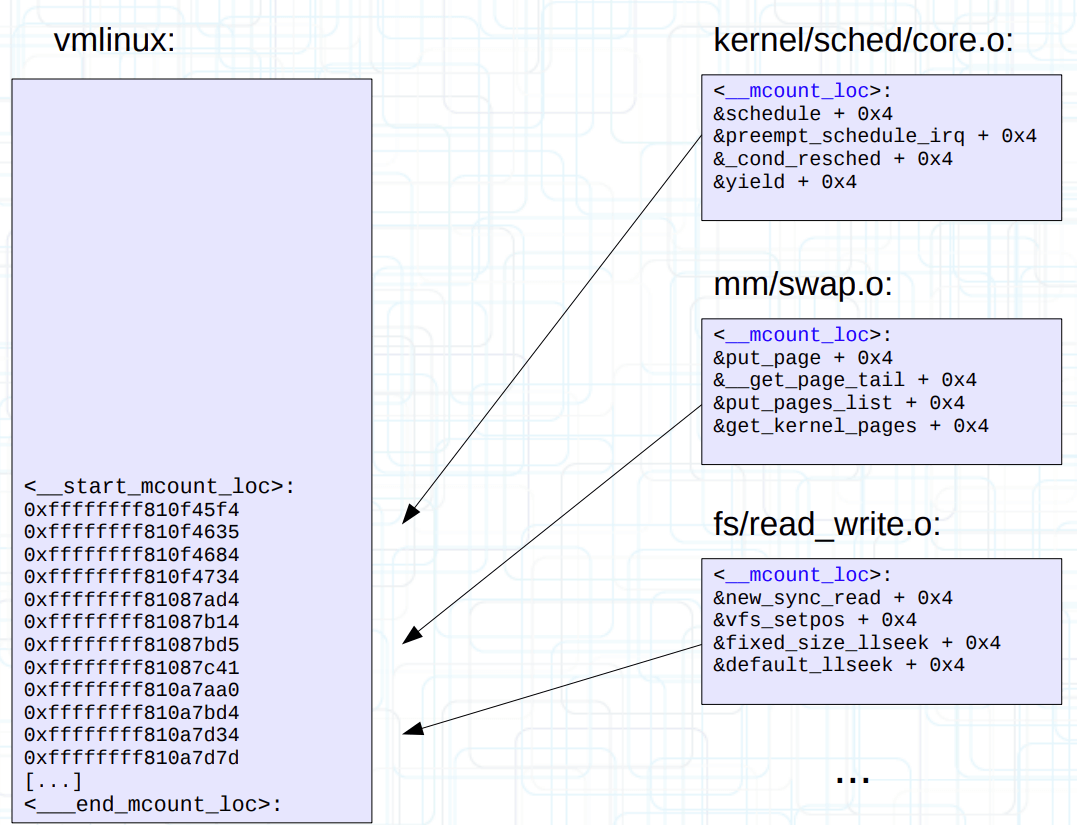
然后使用链接脚本(vmlinux.lds: MCOUNT_REC)定义两个符号 __start_mcount_loc 和 __stop_mcount_loc,将输出节(ELF output section)夹在中间。
一个简化的
MCOUNT_REC实现如下:#define MCOUNT_REC() . = ALIGN(8); \ VMLINUX_SYMBOL(__start_mcount_loc) = .; \ *(__mcount_loc) \ VMLINUX_SYMBOL(__stop_mcount_loc) = .;
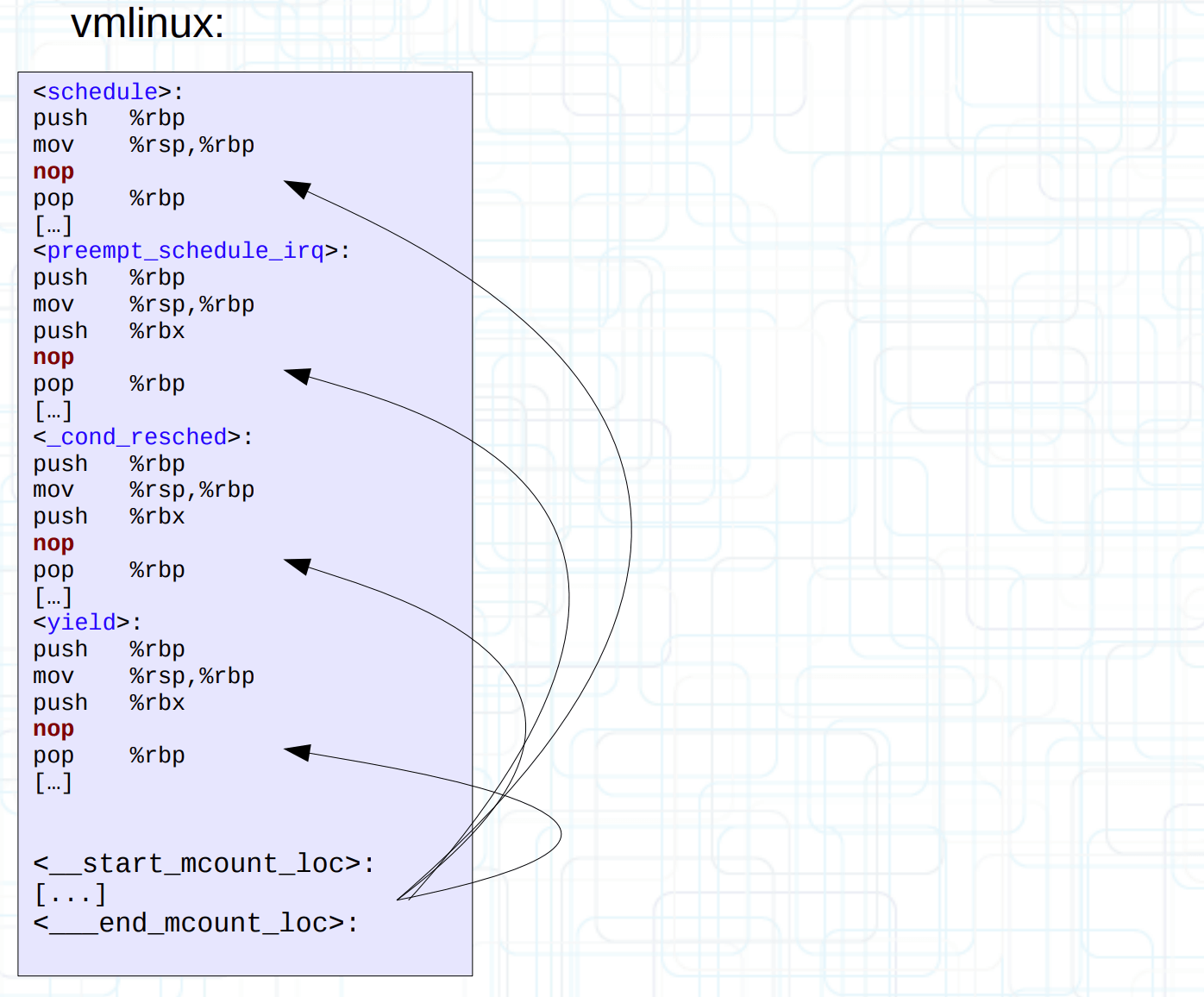
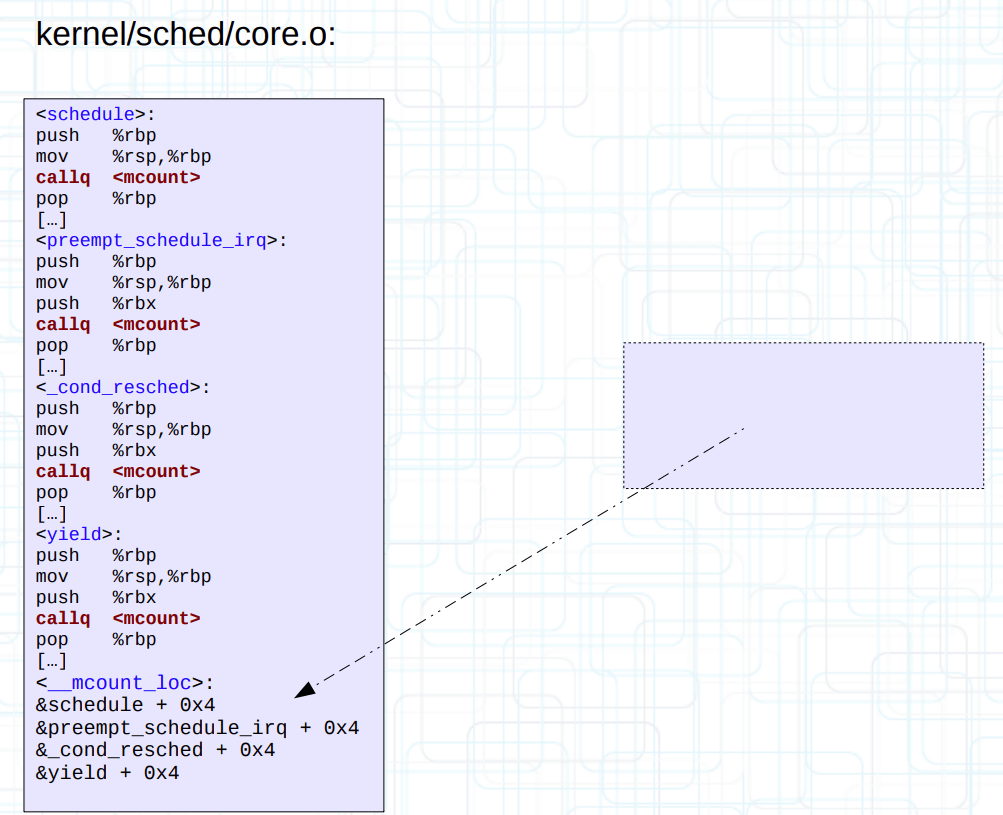
最后在最终生成的 vmlinux 启动阶段时,通过 __mcount_loc 输出节反向定位到每一个 mcount 在 vmlinux 的偏移量,从而动态替换为 nop。MCOUNT_REC 完成使命后,内核还会过河拆桥,将它从 vmlinux 中移除出去(从链接脚本可以看出 MCOUNT_REC 属于 INIT_DATA 的一部分,所以会被移除)。
NOTE: __start_mcount_loc 和 __stop_mcount_loc 这两个符号会被用作数组。
NOTE2: gcc 后来也提供了自动化的 -mrecord-mcount 和 -mnop-mcount 选项。
但是这种粒度是不够的,我们需要为运行时的每一个入口进行精准控制,需要引入描述运行时状态的数据结构。
运行时状态:dyn_ftrace
运行时状态 dyn_ftrace 表面上并不复杂:
struct dyn_ftrace {
unsigned long ip; /* address of mcount call-site */
unsigned long flags;
struct dyn_arch_ftrace arch;
};
dyn_ftrace 通过 ip 记录跳板的地址,flag 控制 ftrace 行为,而 arch 是一些处理体系结构的琐碎事情,x86 下是空实现。初始化只需在 __mcount_loc 移除前拷贝到对应的 ip 字段即可。
总之这些数据结构会作为数组连续分配在若干的页面 ftrace_pages 中(估计 1MB 左右的内存开销)。然后执行排序操作(按跳板地址 ip 排序),可以在某些场合下完成快速查找。
/*
* The dyn_ftrace record's flags field is split into two parts.
* the first part which is '0-FTRACE_REF_MAX' is a counter of
* the number of callbacks that have registered the function that
* the dyn_ftrace descriptor represents.
*
* The second part is a mask:
* ENABLED - the function is being traced
* REGS - the record wants the function to save regs
* REGS_EN - the function is set up to save regs.
* IPMODIFY - the record allows for the IP address to be changed.
* DISABLED - the record is not ready to be touched yet
* DIRECT - there is a direct function to call
* CALL_OPS - the record can use callsite-specific ops
* CALL_OPS_EN - the function is set up to use callsite-specific ops
* TOUCHED - A callback was added since boot up
* MODIFIED - The function had IPMODIFY or DIRECT attached to it
*
* When a new ftrace_ops is registered and wants a function to save
* pt_regs, the rec->flags REGS is set. When the function has been
* set up to save regs, the REG_EN flag is set. Once a function
* starts saving regs it will do so until all ftrace_ops are removed
* from tracing that function.
*/
flag 比较复杂,看看就好。比如 0-18 位表示一个 mcount 会有多少个回调函数的计数器;31 位表示跟踪使能(应该指的是单独的 tracing_on 文件?);30 位表示替换的函数是否需要保存完整的寄存器上下文,因为保存操作是有开销的,没必要的话就要避免这种行为,这也说明了不同的 flag 会影响替换到不同的函数;29 位表示已经保存了上下文。实现细节在不同的版本变化比较大,建议有需要就看特定版本的注释。
NOTE: Steven 提到计数器一开始是设计在 0-29 位(别问为什么是 29,他也不知道),但是我看在具体实现上有过 0-24 和目前 0-18 三个版本。
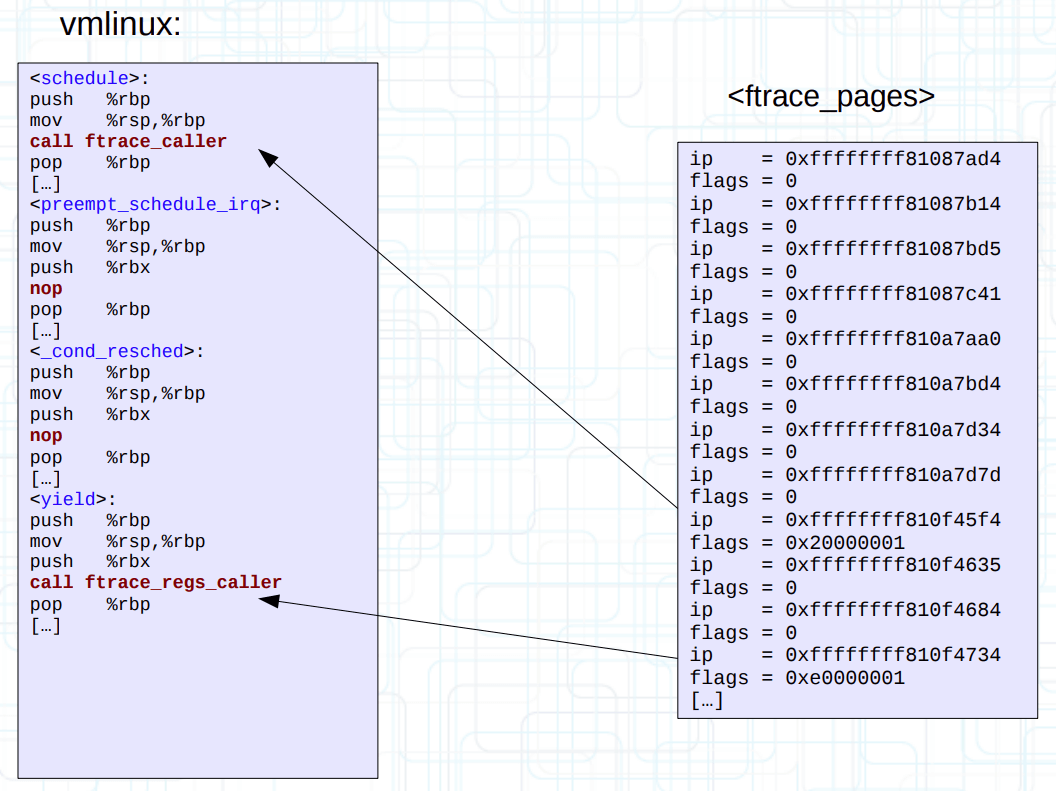
见上图,由于 30 位的差异,启动时的 mcount() 函数被替换为不同的跳板(比如 ftrace_caller)。
运行时修改:INT3
运行时修改比启动时修改要难得多。因为启动时象只有一个主核在执行,而运行时很难确保原子替换指令(不同指令不等长,还会跨缓存行,然后 CPU 按缓存行进行硬件预取操作等等),如果非原子地替换为错误指令,将会产生 GP 异常(General Protection)而引发机器重启。
(自曝八卦)这种复杂事情即使是 Steven 也会碰壁,然后 Steven 问 Intel 解决方案,Intel 装死。

一种解决方案是使用 INT3 断点(0xcc)。因为使用断点会使得 CPU 产生 IPI 中断以完成同步操作(作为一种内存屏障)。个人理解是先在要修改(若干)指令的首个字节上原子替换为 0xcc,执行到这条指令就会触发断点并将 CPU 控制流转移到预先注册好的 do_int3() 异常处理例程,由于触发的 CPU 肯定不是本地 CPU(本地 CPU 正在调用 ftrace 使能函数修改指令),因此只需在断点触发的过程中视为直接跳过 nop(x86 固定 5 字节)即可避免数据竞争。
NOTE: 上面提供的例程链接是 Linux 4.18.20 的实现,新版本的 Linux 内核是模拟 INT3 操作,更加的复杂,有空再找点资料。
回调注册:ftrace_ops
一个简化的 ftrace_ops 数据结构如下所示,它代表一个 ftrace tracer 的操作:
struct ftrace_ops {
ftrace_func_t func;
struct ftrace_ops *next;
unsigned long flags;
int __percpu *disabled;
void *private;
#ifdef CONFIG_DYNAMIC_FTRACE
struct ftrace_hash *notrace_hash;
struct ftrace_hash *filter_hash;
struct mutex regex_lock;
#endif
};
尽管不是重点,还是提一下。ftrace_ops 分为静态和动态分配,前者固定在内核数据段,比如 function、function_graph 这些 ftrace tracer 都是静态分配;后者需要通过动态分配(kmalloc())得到,比如 perf 和 kprobe 使用动态分配。随后内核通过 register_ftrace_function() 将 ftrace_ops 挂载到 ftrace_ops_list 链表上。
需要关注的字段是 func 和 filter_hash,前者指的是跟踪时会调用(替换 stub)的函数,后者指的是需要跟踪的函数(注意内核版本区别,这里是简化的实现)。
NOTE: 如果 filter_hash 为空,那就是跟踪所有函数,反正就是 set_ftrace_filter 文件的意思。
跳板实现:ftrace_caller
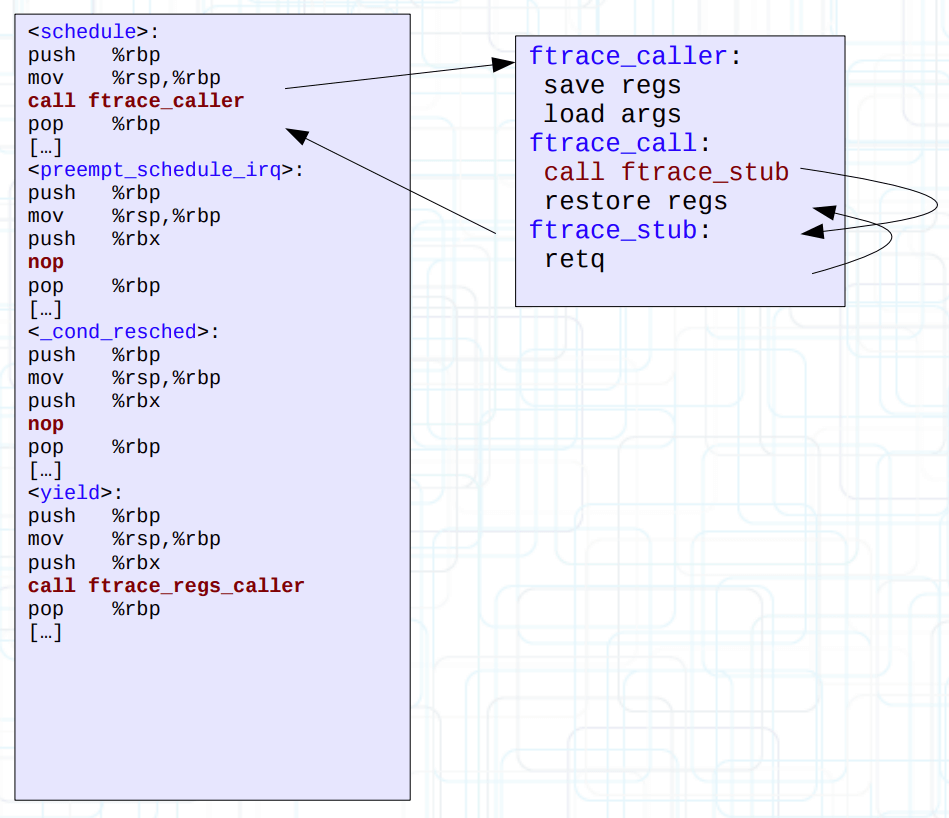
以 ftrace_caller 为例,它本身还是一个什么都不干的函数。
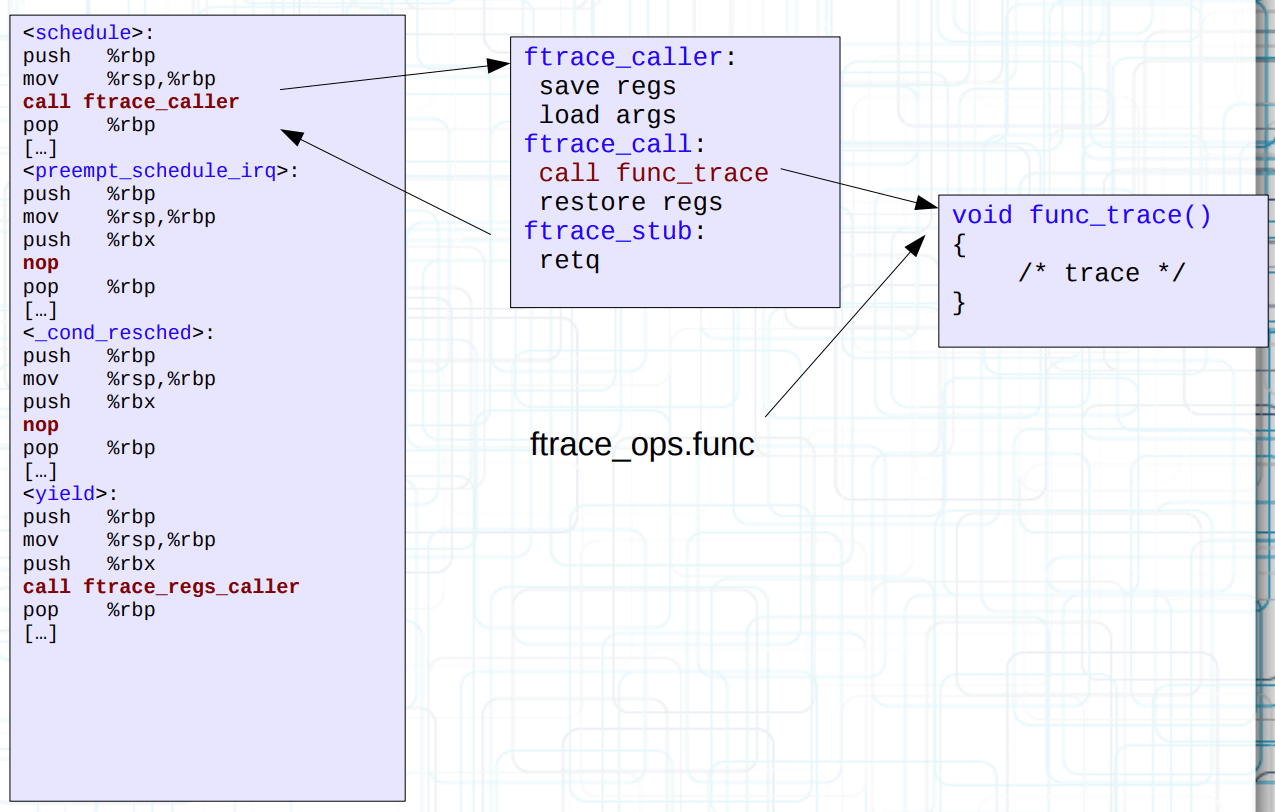
我们可以令 stub 替换为 ftrace_ops 对应的函数,也就是 func 回调。这样内核中的所有函数被可以被 tracer 跟踪。
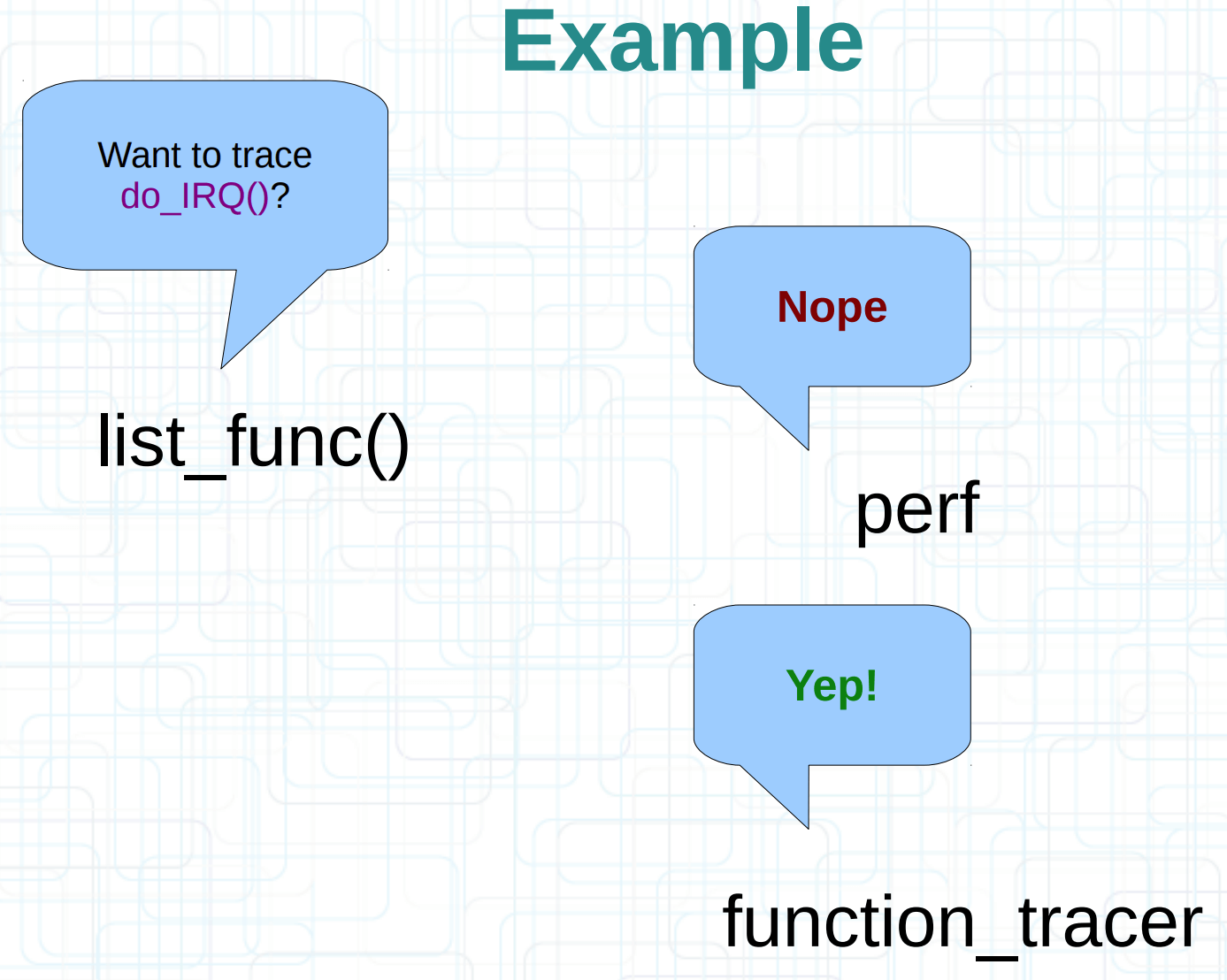
但是 tracer 本身可以多个同时启动,而且不同的 tracer 感兴趣的函数还会不一样,怎么办?
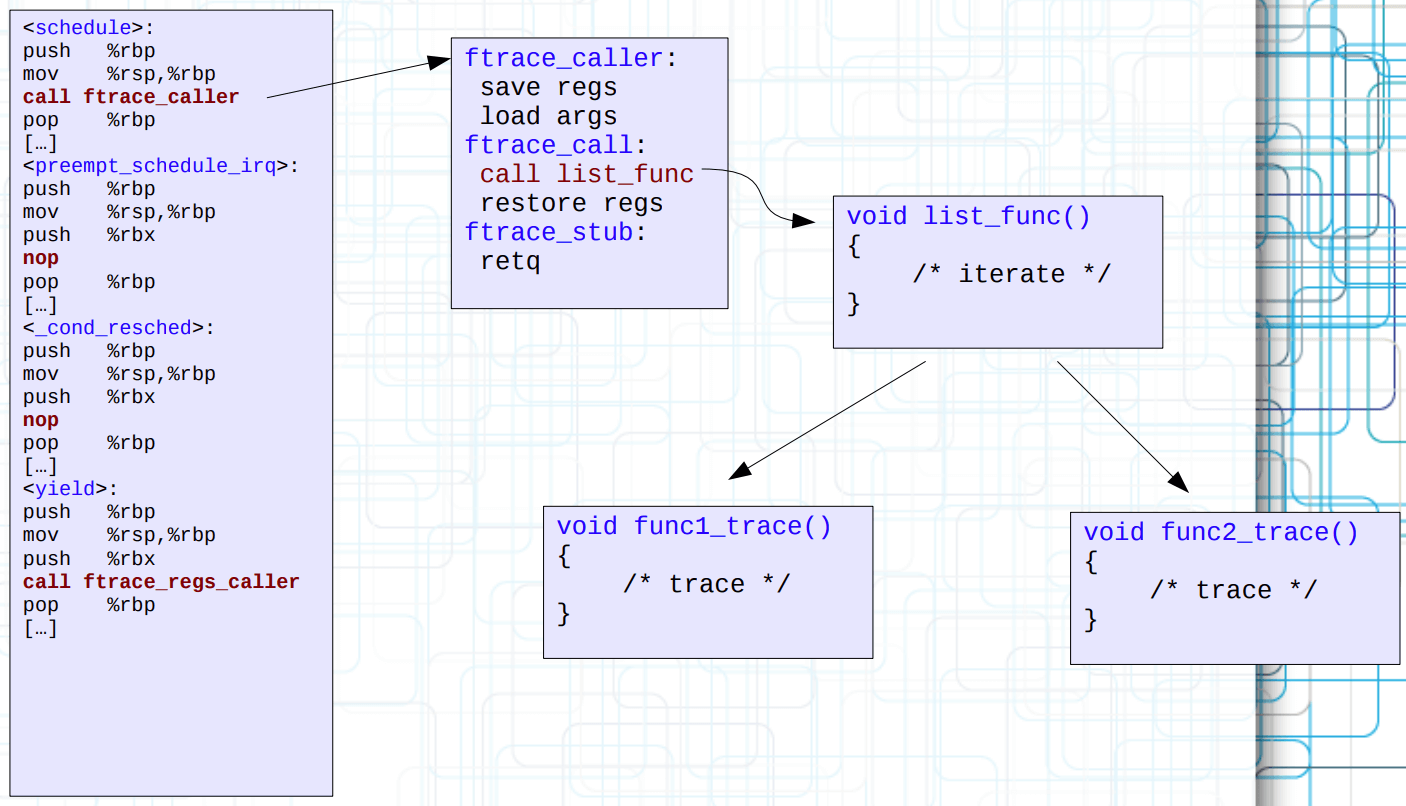
一种做法是令 stub 再次替换为 list_func 以遍历 func,并通过匹配 filter_hash 来解决问题。
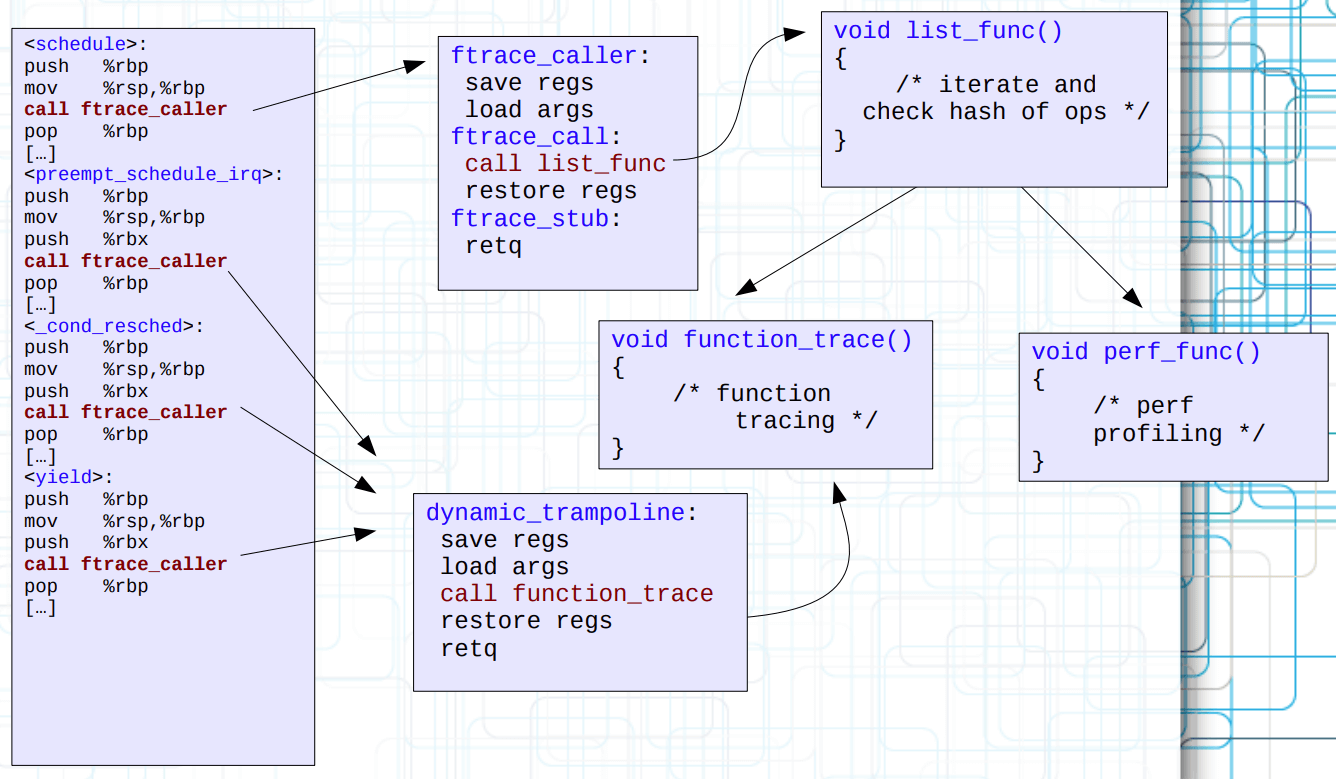
但是每一次都要遍历所有 tracer operations 是相对低效的,Steven 为只有一个 tracer 跟踪的函数单独搞了一个动态跳板(这下连 ftrace_caller 都被换掉了),从而消去了不必要的遍历行为。
NOTE: 演讲稿里还提了动态跳板还没被执行却发生内核抢占的案例,比较懵,有时间再细看。
mcount 优化:fentry
mcount 实现因为是先动了寄存器再跳过去,所以无法记录传参信息(应该说是低效)。gcc 再次提供 -pg -mfentry 选项来解决这个问题。
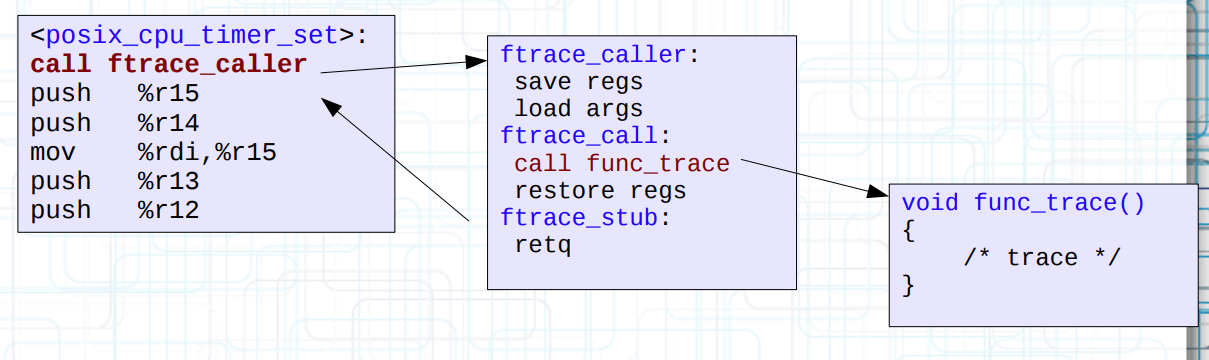
方法很简单,把指令挪到最上面即可。原来的 mcount 符号也改为 __fentry__,然后执行动态替换,如上图所示。
演讲稿后面还秀了一手 live kernel patching 操作,都有这么厉害的跳板了,想怎么改还不行呢。
总结
goto #TL;DR
References
Ftrace Kernel Hooks: More than just tracing – Steven Rostedt
ftrace - Function Tracer – The Linux Kernel
ftrace: Where modifying a running kernel all started – YouTube
RISC-V Ftrace 实现原理 – 泰晓科技