本文简单总结体系结构带来的硬件特性对于程序设计时产生的性能影响。这话说来乱七八糟的,其实就是硬件会影响你的程序性能,虽然看似废话,但我们有必要了解。
当然,这种工作早就有前人整理过并提供了详尽的测试数据,我也只是闲时看文章然后再给出节选和总结,推荐阅读原文(见参考部分)。
比较常见的或者没啥建议的硬件特性就不提了。
4K 混叠
4K 混叠(4k aliasing)指的是一种读最近写的访问模式:先于内存地址 X 执行一个写操作,紧接着于内存地址 Y 执行了一个读操作,其中 X 与 Y 的偏移量为 4KB(的倍数)。我个人理解的意思是由于处理器存在写入缓冲的设计,写入(到写入缓冲)之后的读操作也可以从写入缓冲中得到,但是硬件实现上是只比较内存地址的低 12 位,冒险失败后需重新发射指令,因此存在 4K (\(2^{12}\)) 的问题。
这个现象有意思在于局部性原理失效了:过度「对齐」且读最近写的访问模式,会带来读操作的延迟惩罚(Intel 文档指出可能会增加 5 个时钟周期)。
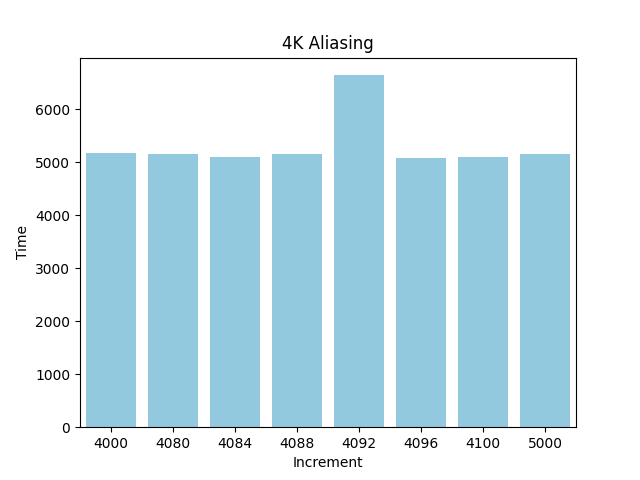
基准测试程序可参考这里,i3-1135G7 得出的结果如上图所示。
核心代码为:
for (int i = 0; i < SIZE; i++) {
a[i] += b[i];
}
其中a和b数组 (int[SIZE]) 相差Increment字节。
执行过程:
Increment: 4000, Time: 5175.4
Increment: 4080, Time: 5158.6
Increment: 4084, Time: 5092.8
Increment: 4088, Time: 5159.6
Increment: 4092, Time: 6641.6
Increment: 4096, Time: 5087.8
Increment: 4100, Time: 5100.8
Increment: 5000, Time: 5156.6
可以看出4092的差值(加上int 4字节则为4k)有非常大的延迟惩罚。
带宽饱和
带宽饱和(bandwidth saturation)指的是体系结构中的一般事实:内存瓶颈比 CPU 瓶颈来得更快。这提示了程序设计时线程数使用的潜在问题,虽然线程数与逻辑 CPU 数相等时有最佳的系统预估性能(只考虑计算资源的前提下),但是如果所有线程都执行内存操作的话,可能使用不到一半的 CPU 数就会达到内存瓶颈。
进一步的讨论是内存读写操作是否经过缓存。直接的结论是不管哪种情况,加入过多线程执行内存操作都会让性能表现变差,只是使用缓存的情况更差。
分支预测
分支预测应该懂的都懂。从问题定位的角度来看,有两种细微差异的情况:分支预测失误(branch misprediction)和分支目标预测失误(branch target misprediction)。差异在于前者指的是 if-else 的分支情况,后者对应更加间接的跳转情况(比如表示多态的虚函数调用)。
有一点性能上的建议,一篇来自 Cloudflare 的文章总结 x86 最好将热路径的代码体积控制在 16KB 的范围内,这个体积不过于为难分支预测器。
DRAM 刷新
DRAM 的电容特性决定内存每 64ms 必须全局刷新一遍,均摊到 8192 行就是 7.8μs。在此期间无法执行内存操作。
这是无法避免的事情,只是说每 7.8μs 总会出现内存延迟上的抖动。
NOTE: 这种现象难以通过测试发现(延迟的影响因素过多),但是有一位硬核网友使用了快速傅里叶的方式分析得到 7.8μs 的刷新间隔,推荐看看。
写入消除
硬件写入消除(hardware store elimination)是一种奇特的特性,如果尝试已经为 0 的值(cache)上再次写入 0,会得到比写入其它数值更高的内存带宽,因为硬件有启发式的设计使得特定的写入操作被消除,其写操作消除量可以到达 50%。(浮点区分 +0 和 -0,只有 +0 存在这种收益。)
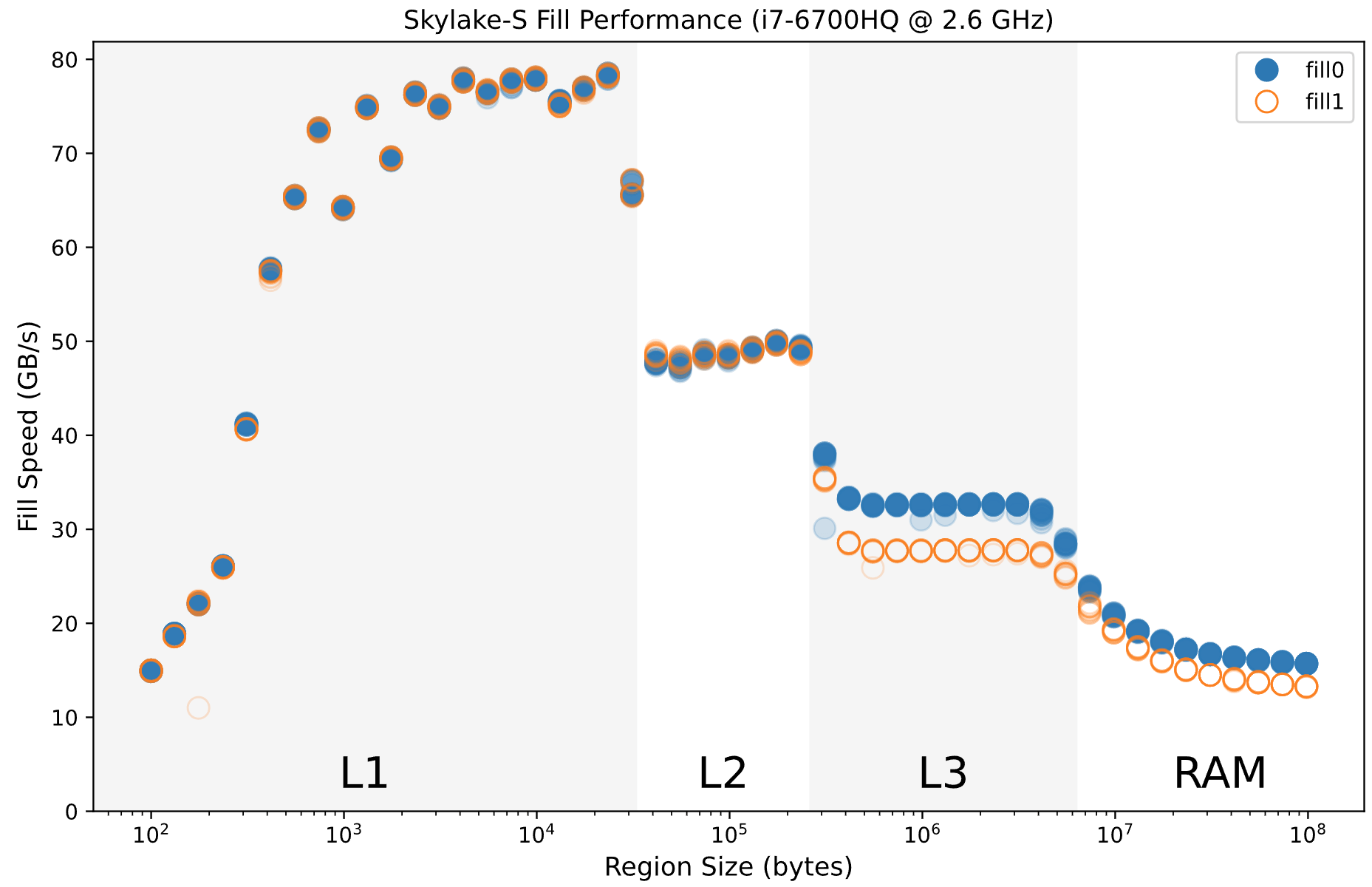 i7-6700HQ 的
i7-6700HQ 的 std::fill 性能测试结果
所以这对于一个开发者来说有什么用?一方面,0 是一个特殊的数字,可以表示为空或者是一个初始的状态;另一方面,冗余的写入是难以避免的。所以……也许有用?比如分配器中常用于对象初始化的的零页(zero page)分配,抹零的页可能大多数区域本来就是零;又比如所谓的无分支编程(branchless programming),不管是否此前判断为 0,直接写进去就是了。
NOTE: 我在 AMD 的 ZEN3 处理器上完全测试不出上述表现,看来这是 Intel 的独家秘方。
NOTE: 其实我也不太懂无分支编程。比如 libuv 有一段代码是明显的反模式,理由是避免写操作对 cacheline 的污染,但这到底有没有道理呢?这需要看编译器有没有真的生成不一样的指令(注释写了 gcc 会这么做,但我没有验证),以及真的做了完善的性能剖析才有结论。
软件预取
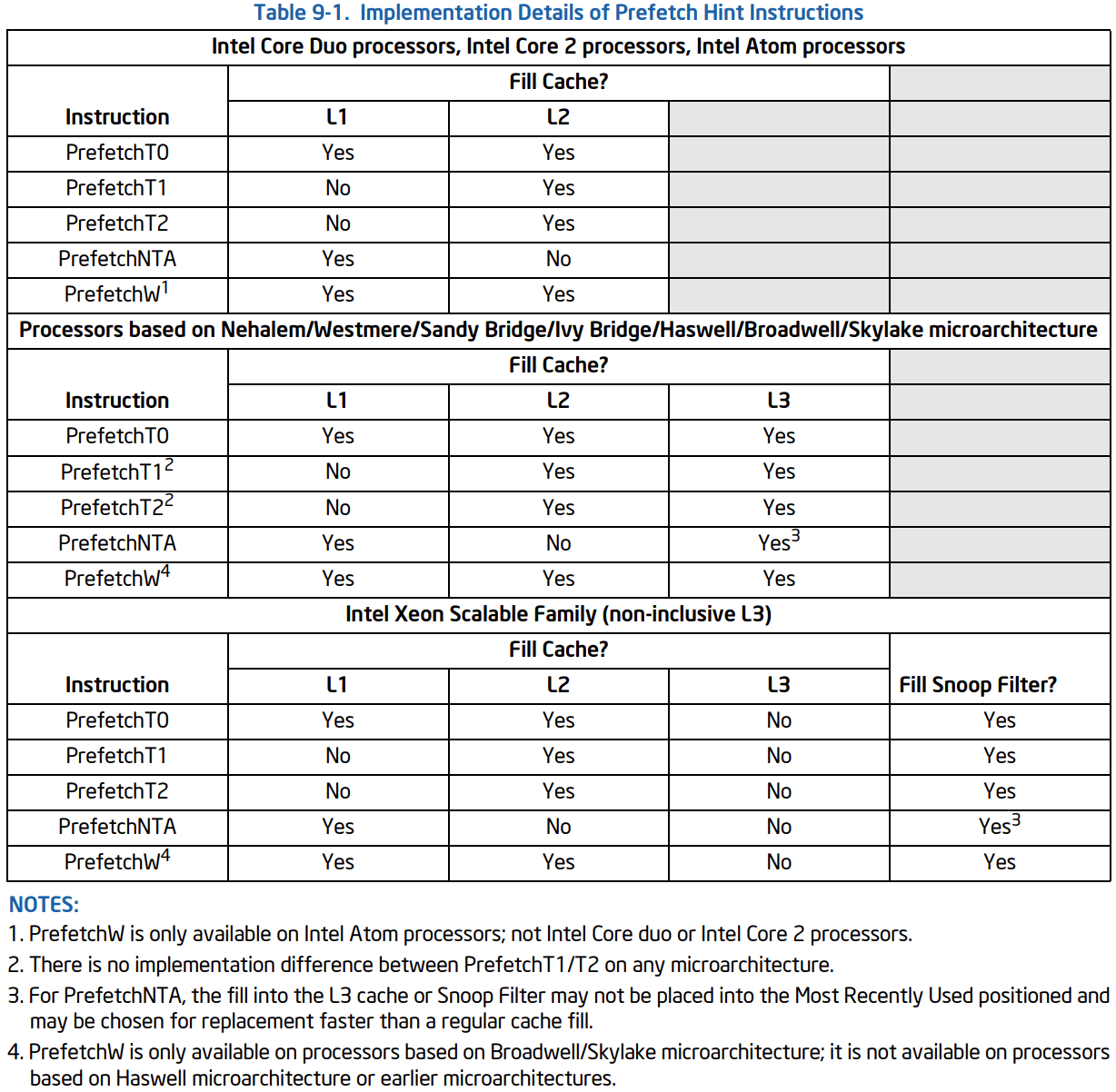 Intel 文档给出的说明
Intel 文档给出的说明
软件预取(_mm_prefetch)有别于硬件预取,前者需要开发者去给硬件提示(hint),具体看上图。
有大佬指出使用合适的软件预取解决数据依赖的问题,可以做到 CPU 计算的吞吐量翻倍。
NOTE: 但是有另一个复杂的问题,软件预取的代码该放在哪个地方最合适?很难说耶。
写入缓冲
写入缓冲(store buffer)多数人应该听说过,前面也提到过,那么它多大呢。当然是不同微架构不一样,比如 Skylake 是 56 个条目大小,Haswell 只有 42 个条目。
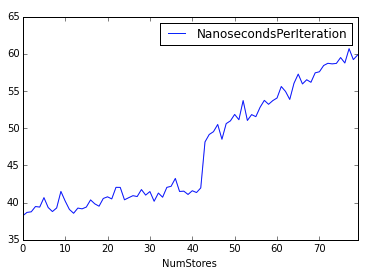 Haswell 架构的容量测试
Haswell 架构的容量测试
了解容量大小可以避免在不合时宜的情况将缓冲提交到缓存而导致意外的延迟。看到上图你应该明白容量范围内外(42-43 附近)的延迟区别。
References
Intel® 64 and IA-32 Architectures Optimization Reference Manual
Hardware effects – Kobzol (github.com)
Don’t make it appear like you are reading your own recent writes – Daniel Lemire’s blog
Hints for Performance Tuning – PETSc Documentation
Branch predictor: How many “if”s are too many? – The Cloudflare Blog
Hardware Store Elimination – Performance Matters
Speculating About Store-Buffer Capacity – Whereabouts Known
What are _mm_prefetch() locality hints? – Stack Overflow