背景
本文翻译了解析 thread_local 实现的演讲:Евгений Ерохин — Thread Local в C++ как он есть。主要是介绍 TLS 数据结构、四种经典 TLS 访问模型(access model)和更高效的描述符模型。
一些不重要的备注:
- 本人不懂俄语,实际使用 Gemini 翻译。
- 重要的地方要是表意模糊我会手动修正,不太重要的地方读者就凑合看吧()
- 图和代码显然也是人工边看演讲边插入的,不是幻觉生成。
- 标题不知道该怎么字面翻译(文化差异?),就挑选了篇幅占比最长的「访问模型」。
- 演讲是 2020 年的,注意文中部分内容的时效性。
- 选这篇是因为我觉得内容很不错,作者是现场直接开 godbolt 跟你聊代码的。
- 但是汉化版会受限于个人认知水平……如有错误还请指正!
- 转录小站那边还有大量演讲稿,更加适合快速阅览(其实我也没全部看完 orz)。
正文部分
好的,那么,请允许我介绍一下我今天报告的主题:C++ 的 thread_local 访问模型。我叫 Женя Ерохин(叶夫根尼·叶罗欣)。首先,我来试着预判并回答你们的第一个问题,那就是我的背景。目前,我是 DINS 公司的一名高级开发人员。我们开发用于实时视频传输的各种服务,比如 RTP 协议。我需要实现大量的 RFC、阅读各种文档等等。在此之前,我在 Paragon Software 工作了十年多,主要负责一个方向。在某个时期,我甚至是 Mac 平台下文件系统驱动程序的主要(甚至是唯一的)开发者。我不得不实现文件系统、从事快照系统、各种引导加载程序、逆向工程以及许多其他系统级的工作。顺便说一下,我们的引导加载程序也使用 C++,驱动程序也都是用 C++ 写的,所以这里的一切都与 C++ 有关。当你做很多逆向工程,深入研究时,总会想看看它内部是什么样的,它是如何工作的。今天,我想向大家介绍我其中一项研究的结果。
thread_local 基础
是的,我想向观众提一个问题,现在就在聊天区里问吧。对于那些还不太明白 thread_local 是什么的人,我先简单描述一下。假设我们有一些变量,我们希望每个线程都拥有它自己的、独立的副本。当一个线程访问某个变量时,它访问的是自己的那份,并且只与自己的这份数据打交道。另一个线程会有它自己的副本,并操作它自己的副本。这只是一个非常简短的概括。
那么,我们以什么为基础呢?我们以 Linux 中的实现为基础。为什么?嗯,因为实际上这是目前支持 thread_local 最多样化、最广泛使用的平台。据我所知,macOS 和 Windows 目前还无法夸耀这一点。
接下来,简单谈谈其演变过程。thread_local 最初是作为 POSIX 的一部分出现的,通过一组命令 pthread_getspecific 和 pthread_setspecific 来实现。在此之前,还需要调用某些函数来准备好这一切。这需要大量的手动工作,而且效率不高。自然,业界不希望一直这样下去,于是编译器开发者们接手了这项工作。他们添加了——起初形式各异,但最终是——__thread(两个下划线)这个关键字,它早在 C 语言中就有了。如果我们在变量声明前加上这个关键字,该变量就成为当前线程的局部变量,只有该线程使用它。每个线程都会有自己的一份拷贝。最终,在 C++11 中,这以 thread_local(一个下划线)关键字的形式,作为标准特性正式引入。
thread_local int t_sumvar;
void increment() {
t_sumvar++;
}
那么,让我们来了解一下 thread_local 在机器码中究竟是什么样子的。假设我们在全局作用域中声明了一个 thread_local 变量 t_some_var,然后我们写一个函数来递增它。
addl $1, %fs:t_sumvar@TPOFF
现在我们来看汇编代码。这里,这一切都变成了一条指令。也就是说,没有一堆函数调用。只有一条指令,为了看得更清楚一点,它相对于 fs 寄存器,在某个偏移量处加 1。也就是执行递增操作。
基本上,这里可能已经很难再优化了(-O2 改到 -O3)。
callq __tls_get_addr@PLT
addl $1, (%rax)
嗯,我们甚至可以给它加上 -shared 编译选项(-fPIC)链接为共享库。噢!这时候出问题了。我第一次看到这个时也是这么想的。一条指令变成了一个 call 调用和一些魔法操作,发生了一些奇怪的事情。那时我为自己总结了一个论点:汇编代码永远反映的是“此时此地”的情况,它往往不能告诉我们事物的全貌。我们稍后会再回到这个代码片段,现在我们继续往下看。
(人工注:作者现场是不区分 fpic 和 fPIC 的,也没所谓了)
在 POSIX 中,我们的工作流程是这样的,实际上现在也仍然如此。为了获取线程特有数据,我们首先需要使用 pthread_key_create 创建一个键(key)。然后,需要将这个键保存在一个全局变量中,这样所有线程才能知道要通过哪个键来访问数据。如果我们想设置数据,就用 pthread_setspecific;如果想获取数据,就用 pthread_getspecific。相应地,之后还要记得用 pthread_key_delete 来清理。当然,还有一个小不便之处,就是我们操作的是 void* 指针。如果我们想要一个结构体,就得自己分配内存,你懂的,需要大费周章。看到这一系列操作,你很容易就能想象出有多少地方可能出错。因此,一个关键字和来自编译器的某种自动化支持是必不可少的。
要摆脱这种复杂性,自然就是使用关键字。它最初以 __thread(两个下划线)的形式出现,后来在 C++ 中演变为 thread_local。正如我所说,一旦指定了这个关键字,数据就变成了线程局部的,并且每个线程都有自己的副本。
那么,我们可以在哪里使用这个关键字呢?
- 全局作用域:在
main函数之前,我们可以定义thread_local int some_variable;。 - 结构体内部:当在结构体内部使用时,我们仍然需要使用
static关键字。这是因为thread_local变量与静态全局变量是近亲。我认为保留这个词是为了让程序员一眼就能看出,这个变量并不属于结构体实例的字段,它会被分开存储。但是,我们可以通过结构体的限定符来访问它。 - 函数内部:就像我们使用
static使得函数拥有一个全局变量一样,thread_local能让函数在每个线程中都拥有一个该变量的独立副本。
我想,到这里应该都清楚了。
另外,从 C++17 开始,我们能够为变量指定 inline 说明符,thread_local 变量也不例外。相应地,如果我们在头文件中定义它,编译后最终只会有一个实例,而不是一大堆分散在不同模块(或者说目标文件)中的副本。
链接基础
还有一个小特性,GNU 中有所谓的 “weak” 符号。我们可以为 thread_local 变量设置 weak 属性。我来稍微解释一下什么是 weak 符号,因为后面会用到。在 GNU 编译器中(也就是在 ELF 格式、Linux 和许多 Unix 系统中),可以将符号定义为 “weak”(弱符号)。在链接的语境中,符号就是函数名或变量名。我们可以说它是弱的,意味着它实际上可以不存在于代码中。通常,如果我们链接某个库,我们必须能找到所有需要的符号,否则就会出现链接错误“符号未解析”。但如果我们将库中的某个符号定义为弱符号,链接器会说:“好的,这个符号没有,但没关系。”唯一的要求是,我们之后在代码中必须显式检查,例如 if (symbol_name != nullptr),来判断它是否存在,如果存在我们才能使用它。
作为工程师,在组织 thread_local 存储时,我们必须考虑什么?
- 我们有一个可执行文件(executable),也就是某个加载的二进制文件,它有
main函数,也就是主线程。对于thread_local变量,会为它创建一个内存块。毕竟,我们有变量,就需要内存来存放它。 - 接着,可能会创建新的线程(threads)。相应地,每个线程都必须有自己的副本。也就是说,必须为每个线程创建一个内存块来存储所有这些数据。
- 我们还有 DSO(Dynamic Shared Object)。在 ELF 格式的术语中,DSO 就是动态共享对象,简单来说就是 DLL 或共享库。当它们被加载时,它们也可能有自己的
thread_local变量。因此,它们也需要为每个使用它们 的线程提供自己的内存块来存储这些变量。 - 在任何时候,都可能有新的线程加入,因此也需要为它们分配存储
thread_local的空间。 - DSO 也可能在任何时候通过
dlopen加载,并通过dlclose卸载。因此,需要为它们分配和释放内存块。 - 线程本身也可能退出。
所以,围绕着一个小小的关键字,背后却是一幅非常有趣且需要周全考虑的动态图景。
让我们慢慢深入了解这一切是如何工作的。首先,我们给 thread_local 变量的生命周期起点下一个稍微粗糙的定义:它始于新线程的创建,或某个共享库的加载(通常是通过 dlopen)。生命周期的终点自然是线程退出(此时必须清理所有 thread_local 数据),或者 DSO 被卸载(通过 dlclose 或在进程结束时)。
为了支持 thread_local,就像全局变量有 .data 和 .bss 段一样,ELF 格式中也添加了两个新的段:.tdata 和 .tbss。
我们都知道,当我们在全局作用域声明一个变量并初始化,比如 int a = 5;,这个 5 会被保存在编译后的可执行文件的 .data 段中。程序启动时,这个 .data 段会被复制到分配给数据的内存页中。如果数据未初始化或初始化为零,它们的信息会记录在 .bss 段中,系统不会在文件中为它分配空间,但会记录其大小并在加载时将其清零。
为了让 thread_local 数据也遵循同样的逻辑,ELF 格式增加了两个新段:.tdata 和 .tbss。逻辑完全相同:当为线程创建数据时,初始化的数据从 .tdata 复制而来,未初始化或零初始化的数据则根据 .tbss 的信息进行准备(清零)。
当然,这其中还涉及到重定位(relocations)。简单说一下什么是重定位,以便我们达成共识。我们有 .text 页,存放可执行代码;紧随其后的是数据页(由 .tdata, .bss 等初始化)。ELF 可执行文件或 DSO 还有一个重定位表。这个表是一系列记录,它告诉动态加载器(负责我们程序运行时的程序):“在我们将代码和数据内容放到地址空间的某个地址后,我们必须在这些地方修正具体的地址,或者填入动态加载器才知道的数据。”
这里展示了两种主要的重定位类型:一种是直接修正代码中的地址,但这并不总是这样。因为,你肯定知道有位置无关代码(Position Independent Code, PIC)和位置相关代码。当我们用 -fPIC 选项编译时,会生成位置无关代码,这些对代码的重定位操作会转移到数据页中专门组织的表里(我们马上会讲到),代码本身保持不变。这样,代码页就可以在多个进程间共享。
Поддержка в ELF(ELF 中的支持)
* Новые релокации(新的重定位项)
- R_X86_64_DTPMOD64
- R_X86_64_DTPOFF64
* Или объединенные в одну запись(或合并为一条记录)
- R_X86_64_TLSLD
与 thread_local 一起出现的重定位类型中,我们主要会看到 R_X86_64_DTPMOD64 和 R_X86_64_DTPOFF64,以及一个将它们结合起来的重定位类型 R_X86_64_TLSLD。
DTPMOD64:告诉加载器,请在指定地址处放入“模块ID”。在链接和二进制文件的术语中,可执行文件和 DSO 都被称为模块。DTPOFF64:请求加载器放入thread_local数据相对于其模块存储块基地址的偏移量。
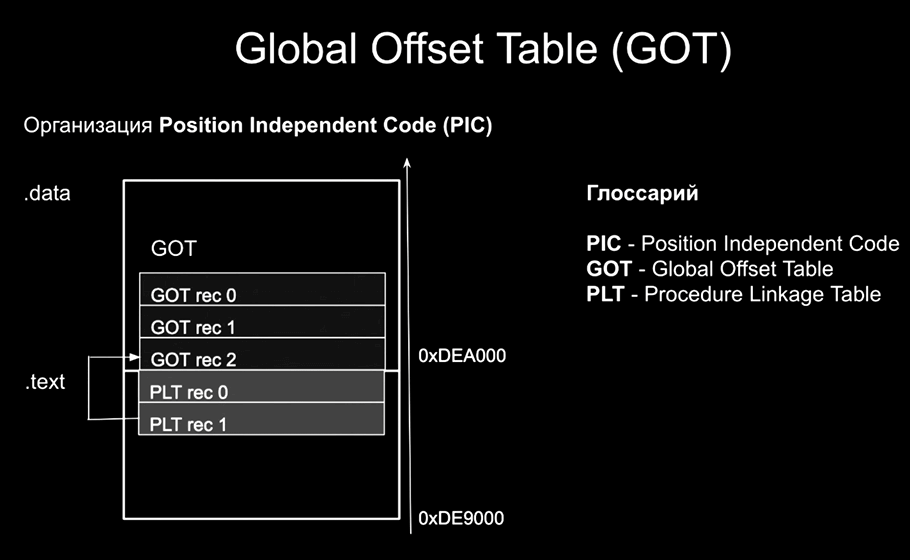 PLT 和 GOT 的简单图示
PLT 和 GOT 的简单图示
为了理解后续内容,我们需要了解 PIC 是如何工作的。地址从下往上增长。最下面是代码页 .text,存放我们的程序。上面是数据页。为了处理重定位,引入了一个特殊的表:GOT(Global Offset Table,全局偏移表)。它的每个条目都是一个指针大小,我们在这里存放所有我们需要的指针。如果我们需要另一个目标文件中的变量,我们就通过重定位表请求动态加载器:“请把那个变量的地址放到 GOT 的这个位置”。然后我们的代码就可以通过 GOT 间接访问它。
如果是函数调用,它们也需要地址。这些地址也放在 GOT 中,但为了支持延迟绑定(lazy binding),还增加了一些小的跳板函数(trampolines)——即 PLT(Procedure Linkage Table)。首次调用函数时,会跳转到 PLT,PLT 再从 GOT 中获取地址。虽然 PLT 本身与 thread_local 关系不大,但你会在汇编示例中经常看到它。
总结一下这张幻灯片:我们有一个外部的表(GOT),可以存放重定位后的各种地址,然后我们从那里使用它们。这个表也将被用来存放 thread_local 的各种指示信息,比如模块ID和存储区内的偏移量。
TLS 概念
现在我们引入 TLS(Thread Local Storage)的概念,这正是我们存放 thread_local 数据的地方。我们有两种模式:静态 TLS 和动态 TLS。
- 静态 TLS:基本上在每个线程启动时创建,其大小是预先知道的。
- 动态 TLS:为通过
dlopen加载的库创建。
Алгоритм формирования Static TLS
Статический TLS формируется динамическим линковщиком на запуске программы
1. Добавляем TLS исполняемого файла (секции .tbss .tdata)
2. Загружаем прилинкованные DSO
3. Добавляем TLS от загруженных DSO (секции .tbss .tdata)
4. Выделяем один блок на все участвующие модули
5. Некоторые! Рантаймы могут добавлять запасной кусок (surplus)
静态 TLS 的形成算法
静态 TLS 由动态链接器在程序启动时形成
1. 添加可执行文件的 TLS(.tbss、.tdata 部分)
2. 加载已链接的 DSO
3. 添加来自已加载 DSO 的 TLS(.tbss、.tdata 部分)
4. 为所有参与模块分配一个块
5. 某些!运行时可能会添加备用部分(surplus)
计算静态 TLS 大小的算法如下:我们启动应用,控制权交给动态加载器。加载器将我们的二进制文件映射到内存,查看它依赖哪些共享对象,构建一个依赖图,然后深度优先地依次加载它们。当整个依赖图构建完毕,所有依赖库都加载后,加载器会检查每个模块(二进制文件或 DSO)的 .tdata 和 .tbss 段,并计算它们的总大小。这个总大小就是我们静态 TLS 存储区的大小。这样,我们就满足了所有已加载对象的需求。此外,通常还会增加一个小小的盈余(surplus),比如 1KB 或 2KB,以备后续不频繁的 dlopen 加载使用,这样就可以利用这块空间,而不用分配新的内存块。
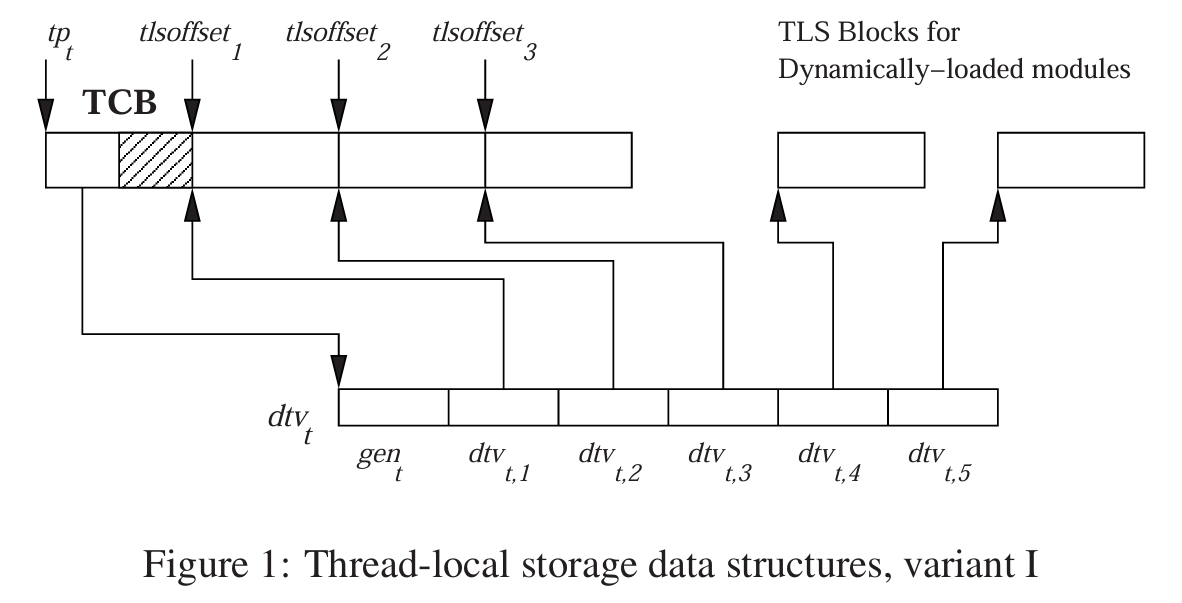
现在让我们进入更多细节。TCB(Thread Control Block,线程控制块)。这是管理任何线程整个生命周期的核心结构。线程生命活动所需的一切都聚集在那里。这里不能不提我们应该感谢谁——Ulrich Drepper。他实现了原生线程库(NPTL),我们今天的 thread_local 也应归功于他。下面那个链接是主要文档,其中描述了当时几乎所有可能的处理器平台上的各种实现细节和重定位方式。因为我展示的重定位类型只是现有庞大体系中的冰山一角。程序编译后,你基本上只会看到两三种重定位,其余的都在静态链接阶段被处理掉了。
https://uclibc.org/docs/tls.pdf
现在让我们看看交互是如何进行的。我们的出发点是 TP(Thread Pointer,线程指针)。这就是我们在 x86-64 平台上从 fs 寄存器中获取的东西。每个线程的 TP 都指向其 pthread 结构,该结构的第一个字段通常是一个指向 DTV(Dynamic Thread Vector)数组的指针。我们马上会讲到 DTV。
我们来看看线程控制块(TCB)中发生了什么。除了指向 DTV 的指针,这里还有很多其他数据,如各种标志、线程启动时要调用的函数等。在 TCB 的末尾,紧跟着我们之前计算好的静态 TLS。
- 首先是二进制文件本身的 TLS,它需要的内存被分配在这里。
- 接着是下一个库的 TLS,依此类推。每个库在这里都有自己的存储区。这整个上半部分,即附加在 TCB 之后的部分,就是静态存储区。
那么我们如何访问它呢?为此,使用了一个辅助向量 DTV。
- 索引 0:是代际(generation)编号。我稍后会解释。
- 后续元素:是一个指针数组,指向每个模块各自存储区的基地址。索引为 1 的指针指向可执行文件的存储区基地址,接着是下一个库的,以此类推。
- 动态部分:如果我们频繁使用
dlopen,显然我们无法预先分配足够大的内存来满足所有可能的动态加载需求。我们必须更具动态性。因此,对于单独加载的库,需要分配它们自己的内存块。当然,这里做了优化:这些块并不会立即分配,而是在真正需要时才分配。如果某个线程从未接触过某个库,那就没必要为它分配内存,以免浪费资源。
关于开头的代际编号,它告诉我们什么?由于系统是动态的,它有自己的生命周期。模块可以被添加或移除。如果每次都以竞争的方式遍历所有线程去修改每个线程的 DTV,那是没有意义的。因此,每次访问时,我们都会检查它的代际编号是否与全局的代际计数器相符。当 dlopen 一个带有 thread_local 变量的对象时,这个全局计数器会增加。相应地,在下次访问这个 DTV 时,我们就会检查代际编号。当库被卸载时,我们同样增加这个计数器。
我希望通过这个图表,大部分内容应该都清楚了,但我们稍后肯定会再看一些 уточнения。
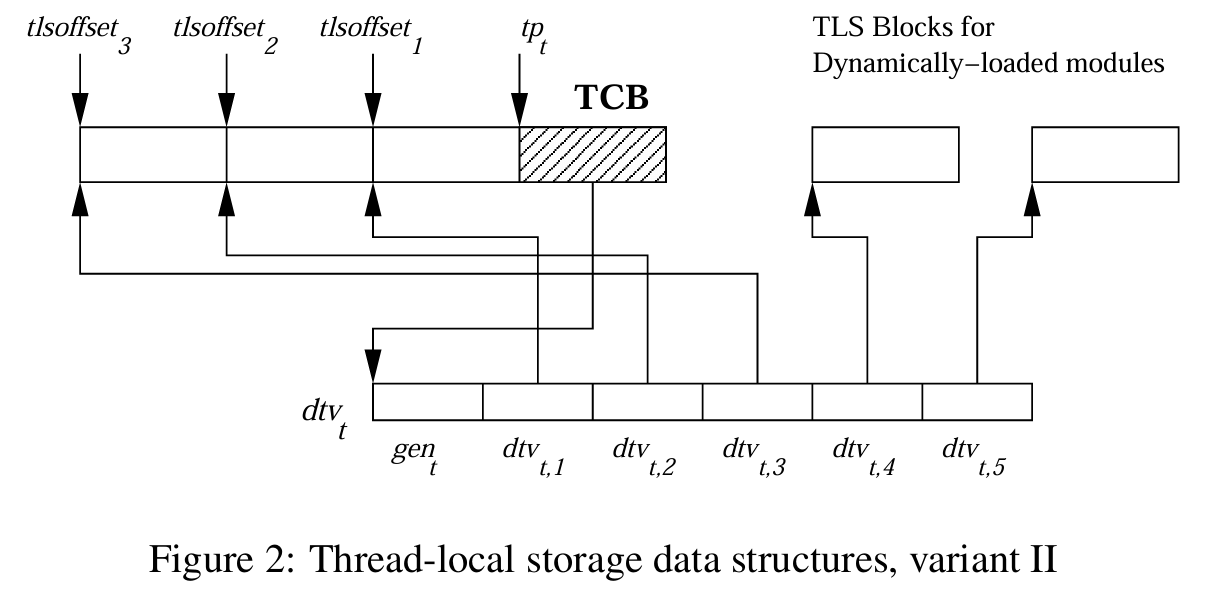
实际上,在 Drepper 的原始论文中有两种模型。为了不让大家眼花缭乱,我先说一下,它们几乎是相同的。区别只在于 线程指针 指向哪里。
- 模型一:线程指针指向结构的开头,TLS 布局在它的右边(即更高的地址空间)。
- 模型二:线程指针指向中间。右边(高地址)是 TCB 本身,左边(低地址)是静态存储区,依次是可执行文件、下一个加载的库,等等。
TCB 仍然指向相同的 DTV 向量,所有基地址也同样有效,它们根据索引指向各自模块的基地址。动态部分也是一样。
当我在 meetup 上试讲这个报告时,我问大家会选哪个方案,大多数人倾向于第一种,因为引用一个结构的中间位置,感觉有点奇怪。但实际上,胜出的是第二种方案。这个方案的优点在哪里,为什么这种复杂性能胜出?因为在编译阶段,编译器无法确定它将为哪个内核、具备哪些特性的系统进行编译,它预先并不知道这个 TCB 的确切大小。因此,这种方案允许运行时扩展 TCB 并添加新字段,因为 DTV 始终从零偏移量处访问。而静态 TLS 全部布局在低地址区。实际上,DTV 也有带负偏移量的元素,包含长度等信息,但这些是细节,对整体理解影响不大。
现在让我们看看这一切是如何工作的,以及有哪些变体。
在所谓的经典 TLS 模型中,我们有四种模型,实际上分为两组。两种用于动态库(即可共享库),两种用于可执行文件(exec 告诉我们这是可执行文件)。
- General Dynamic (GD):最重、最强大的模型,必须处理最棘手的边界情况。
- Local Dynamic (LD):一个更轻量级的动态模型。
- Initial Exec (IE):用于可执行文件的稍重模型。
- Local Exec (LE):最简单的模型。
我们从最重量级的开始看,这样其他的就更容易理解了。
General Dynamic (GD)
+--------+ +--------+ +--------+
| BIN | | DSO 1 | | DSO 2 |
| | | | | |
| TLS |<----->| [x] |<----->| TLS |
| | | | | |
+--------+ +--------+ +--------+
这是最复杂的模型。编译器在编译共享对象时(或者任何时候使用 -fPIC 编译,即位置无关代码),它遇到了一个通过 extern 声明的变量。我们的 DSO-1 并不知道这个变量存储在哪里,它可能在可执行文件的静态 TLS 中,也可能在另一个共享对象的动态 TLS 中。编译器拥有的信息极少,只知道有这么一个符号,并且有人想用它。
为了获取 TLS 本身的地址以及如何处理它,下面这个函数会帮助我们。它直接取自 glibc,虽然看起来很吓人,但实际上它只是组织了我们从 TCB 到 TLS 的那个相当简单的遍历过程。
/* 生成代码,仔细甄别 */
// 人工备注:往视频简单对照了一下,基本接近真实代码,gemini 是不是有点哈人了……
void* __tls_get_addr(tls_index* ti) {
// 简化逻辑
dtv_t* dtv = THREAD_DTV(); // 1. 从线程指针获取 DTV
if (dtv->generation != GL(dl_tls_generation)) {
// 2. 如果代际编号过时,更新 DTV
dtv = _dl_update_slotinfo(ti->ti_module);
}
void* p = dtv[ti->ti_module].pointer.val; // 3. 从 DTV 获取模块的 TLS 块指针
if (p == NULL) {
// 4. 如果未分配,则分配
p = _dl_allocate_tls(dtv);
}
return p + ti->ti_offset; // 5. 返回基地址 + 偏移量
}
// 人工提取的幻灯片代码
void *__tls_get_addr (GET_ADDR_ARGS)
{
dtv_t *dtv = THREAD_DTV ();
if (__glibc_unlikely (dtv[0].counter != GL(dl_tls_generation)))
return update_get_addr (GET_ADDR_PARAM);
void *p = dtv[GET_ADDR_MODULE].pointer.val;
if (__glibc_unlikely (p == TLS_DTV_UNALLOCATED))
return tls_get_addr_tail (GET_ADDR_PARAM, dtv, NULL);
return (char *) p + GET_ADDR_OFFSET;
}
它接收一个指向 GOT 中重定位条目的指针,那里存放着两个我们的重定位值:模块 ID 和这个特定变量相对于该模块 TLS 的偏移量。我要强调一下,偏移量对于所有线程都是相同的,因为虽然每个线程有自己的数据块,但布局是一样的,只是数据块的基地址不同。
让我们看看它是如何工作的。
- 第 35 行(
__tls_get_addr位于第 33 行)使用了一个宏THREAD_DTV,它做了一件非常简单的事情:它通过fs寄存器获取第一个元素,也就是指向我们 DTV 的指针,并返回它。也就是通过线程指针,我们得到了 DTV。 - 然后,我们从 DTV 中取出它的计数器(即代际编号),并与全局代际编号进行比较。
- 如果它们不一致,我们就走另一条路径,更新这个 DTV 向量以适应新的变化(模块增加或删除)。然后执行完全相同的操作,只是这里手动做了一些尾部优化等。
- 接着,通过从 GOT(由加载时的链接器提供)获取的模块 ID,(结合 DTV)我们取得了基地址的指针。这个
pointer.val就是存储我们 TLS 块的基地址。 - 检查它是否已分配,当然,因为它可能尚未分配。如果未分配,就需要分配这个 TLS,然后继续同样的路径。
- 最后,当我们通过 DTV 获取到模块的 TLS 基地址后,只需将其与从 GOT 中获取的固定偏移量相加,即可得到该线程局部变量的实际内存地址。(人工注:这句原话很含糊,因此改用意译。当然也是 AI 修正的,我不懂俄语啊)
在 GOT 中,我们会有两个连续的重定位:模块 ID 和偏移量。这完全保证了我们能遍历整个结构,获取基地址和偏移量,无论是在静态 TLS 还是动态 TLS 中。
https://godbolt.org/z/QfvmAV
希望到这里大家都明白了。我们来看看代码中的样子。我们当然要用 Compiler Explorer,非常感谢 Matt Godbolt 做了这么棒的工具。
// -O3 -fpic --shared
extern thread_local int t_glob;
extern thread_local int t_glob_with_val;
void fn()
{
t_glob++;
t_glob_with_val += 2;
}
我们声明了两个 thread_local 变量。它们都带有 extern 关键词,意味着我们不知道它们具体定义在哪里。
_Z2fnv: # @_Z2fnv
pushq %rax
cmpq $0, _ZTH6t_glob@GOTPCREL(%rip)
jne .LBB0_1
# 第一条指令
data16
leaq t_glob@TLSGD(%rip), %rdi
# 第二条指令
data16
data16
rex64
callq __tls_get_addr@PLT
# 第三条指令
addl $1, (%rax)
# ...
这是我们感兴趣的汇编块。开头有一些魔法,我们先不管它。我们感兴趣的是这三条指令。
第一条指令(lea)带有几个前缀,这些前缀实际上是占位符。因为这是一个重量级模型,静态链接器在构建我们的程序时,可能会尝试将其替换为更轻量但占用更多内存、指令更少、开销更小的模型。想了解更多细节,可以参考 Ulrich Drepper 关于 thread_local 的原始论文。
第二条指令(call)调用我们钟爱的 __tls_get_addr。
这里发生了什么?相对于 rip 寄存器(当前执行位置的指针),我们访问数据页中的一个地址,即我们的 GOT。这条指令实际上是获取了 GOT 中一个特定结构的地址,该结构包含了模块 ID 和偏移量。
我再说一遍,以免太难理解:我们用这条 lea 指令定位了 GOT 中的结构。这个结构的地址作为第一个参数放入 rdi 寄存器。然后我们调用 __tls_get_addr,它从 GOT 的这个条目中获取模块 ID 和偏移量,并通过 rax 寄存器返回当前线程的具体地址。
接下来(第三条指令)就是我们的递增操作 addl $1, (%rax)。
# 接上面代码
cmpq $0, _ZTH15t_glob_with_val@GOTPCREL(%rip)
jne .LBB0_3
.LBB0_4:
data16
leaq t_glob_with_val@TLSGD(%rip), %rdi
data16
data16
rex64
callq __tls_get_addr@PLT
addl $2, (%rax)
popq %rax
retq
我们可以顺便看一下,如果我们有另外的操作,对另一个变量进行递增,会发生什么。因为是另一个变量,我们同样不知道它在哪里,所以我们执行完全相同的操作。它们看起来一模一样。这里我们做了 += 2。结果就是 addl $2, (%rax)。
请记住这个模式,后面的幻灯片会用到。
Local Dynamic (LD)
+--------+ +--------+
| BIN | | DSO 1 |
| | | |
| | | [x] |-----+
| | | | |
| | | TLS |<----+
| | | |
+--------+ +--------+
https://godbolt.org/z/g3y8uW
// -O3 -fpic --shared
static thread_local int t_glob = 0;
static thread_local int t_glob_with_val = 5;
void fn(int& val2)
{
t_glob++;
t_glob_with_val += 2;
}
在这个模型中,我们拥有的信息稍多一些。我们同样是用 -fpic 编译代码,这很可能是一个共享库,但这次我们访问的是一个在同一个目标文件中声明的本地变量。因此,编译器有了更多数据,它至少知道变量在哪里。
_Z2fnRi:
pushq %rax
leaq _ZL6t_glob@TLSLD(%rip), %rdi
callq __tls_get_addr@PLT
addl $1, _ZL6t_glob@DTPOFF(%rax)
addl $2, _ZL15t_glob_with_val@DTPOFF(%rax)
popq %rax
retq
让我们看看如何稍微优化一下。由于它们可以存储在静态或动态存储区中,对于第一个变量,我们做的和之前完全一样。但是这里的占位符前缀消失了,代码变得更小、更漂亮了。我们有一个 TLSLD 重定位,它实际上是同一种指向 GOT 的重定位,那里存放着模块 ID,而偏移量则设为 0。我们马上会看到为什么。
__tls_get_addr 返回的是属于这个模块的 TLS 基地址,加上了零偏移量。接下来发生了什么?这个基地址我们可以立即用于两个本地变量:第一个和第二个。因为我们在这里得到了基地址(第二个参数偏移量为 0),我们只需加上我们变量的具体偏移量即可,这些偏移量编译器是预先知道的,因为它自己就是负责布局它们到内存中。我们的生活稍微简化了一些。
Initial Exec (IE)
+-------------------------------------------------+
| BIN |
| +-------+ +--------+ ... +--------+ |
| | Obj 1 | | Obj 2 | | Obj N | |
| | | | [x] |------------>| [Def] | |
| | | | | | | |
| +-------+ +--------+ +--------+ |
| \ |
+-----------------------\-------------------------+
\
\
\
v
+--------+
| DSO |
| [Def] |
+--------+
https://godbolt.org/z/BjW68P
// -O3
#include <stdio.h>
extern thread_local int t_glob;
int main(int argc, char** argv)
{
t_glob++;
return 0;
}
现在是我们的可执行对象。不再是 PIC 代码,事情更简单一些。但这是这样一种情况:在目标文件中,thread_local 变量被声明为 extern,我们不能完全确定它是在某个共享对象中,还是在同一个二进制文件的另一个目标文件中。也就是说,编译器有一些信息,但并不完整。
main: # @main
pushq %rax
# 魔法,先不管
movl $_ZTH6t_glob, %eax
testq %rax, %rax
je .LBB0_2
callq _ZTH6t_glob
.LBB0_2:
# 感兴趣的部分
movq t_glob@GOTTPOFF(%rip), %rax
addl $1, %fs:(%rax)
xorl %eax, %eax
popq %rcx
retq
# 重复的部分
_ZTW6t_glob: # @_ZTW6t_glob
pushq %rax
movl $_ZTH6t_glob, %eax
testq %rax, %rax
je .LBB1_2
callq _ZTH6t_glob
.LBB1_2:
movq %fs:0, %rax
addq t_glob@GOTTPOFF(%rip), %rax
popq %rcx
retq
这里有一点魔法,我们稍后会回来。我们感兴趣的是这几行。我们如何获取地址?我们使用 GOTTPOFF 重定位。它表示“从 GOT 中获取相对于线程指针的偏移量”。助记符 GOTTPOFF(GOT Thread Pointer)很直观。重要的是,那里应该是静态 TLS 中的偏移量。然后我们从 GOT 中取出这个偏移量,并相对于我们的线程指针(fs 寄存器)得到最终地址。记住,我们的静态 TLS 位于线程指针的左侧(低地址),所以这里的偏移量会是负数。我们把它加到 fs 上,就得到了最终地址。
原则上很简单。这里仍然有很多魔法,我们稍后会再谈。
Local Exec (LE)
Переменные находятся локально в основном исполняемом файле
- Смещение заранее известно относительно регистра fs
- Самый дешевый доступ из всех моделей
变量在主可执行文件中是局部的
- 相对于 fs 寄存器的偏移量预先可知
- 是所有模式中成本最低的访问方式
https://godbolt.org/z/YkQUrK
这是我们最理想的情况。我们有一个目标文件,其中的 thread_local 变量与访问它的代码在同一个目标文件中声明。编译器拥有关于它位于何处、如何布局等的全部信息。
// -O3
#include <stdio.h>
static thread_local int t_glob = 0;
int main(int argc, char** argv)
{
t_glob++;
return 0;
}
main: # @main
addl $1, %fs:_ZL6t_glob@TPOFF
xorl %eax, %eax
retq
_ZL6t_glob:
.long 0 # 0x0
我们实际上回到了第一个代码片段。这就是我们的理想情况,thread_local 变量被递增,最终只变成一条命令,相对于我们的线程指针(记住是 fs 寄存器),在一个预先知道的地址(t_glob@TPOFF,相对于线程指针的偏移量)上操作。我想这里应该非常清楚了。
实际上有一个小的优化技巧 -ftls-model=initial-exec。当我们编译库时,或者只是编译一些我们仍想链接到二进制文件中的 PIC 代码时,我们可以强制要求编译器使用 Initial Exec 模型。这给了我们什么好处呢?我们有机会使用一个更简单的、没有额外间接寻址的模型,但同时我们失去了使用 dlopen 的能力,因为如果我们有动态存储,我们就无法通过这种模型访问它们。这样的应用程序将无法工作。但作为交换,我们在速度上获得了很大的提升。
C++ 标准
那么,标准实际上是怎么说的呢?我不会让你们逐字阅读这些条款(图略),我用自己的话简单概括一下。
- 动态初始化:对于
static存储期和thread存储期的块作用域变量,其动态初始化始于代码执行流第一次进入其声明时。 - 初始化完成:只有当它们的初始化完全结束后,才认为它们被完全初始化了。
- 异常安全:非常重要的一点是,如果在初始化期间抛出了异常,那么这些变量被视为未初始化。当下次访问这些数据时,线程必须再次尝试初始化它们。这实际上是一个非常重要的句子,我希望我们有时间的话,会展示一些与之相关的有趣之处。
- 重入:如果控制流在初始化期间递归地进入,则行为是未定义的(Undefined Behavior)。
接下来是析构。标准关于对象销毁是怎么说的呢? 对于已初始化的对象,如果它们的生命周期已经开始:
- 对于静态对象,析构在退出
main函数或调用std::exit时执行。 - 对于
thread_local对象,其生命周期在线程退出其主函数或调用std::exit时结束。 - 所有
thread_local变量的析构,执行必须与所有静态析构函数的启动呈 happens-before 关系。也就是说,thread_local的析构必须在静态变量(如全局变量)的析构开始之前完成。
很明显,到目前为止我们还不清楚很多事情,因为周围发生了很多魔法。让我们试着搞清楚它。
// https://godbolt.org/z/Yh_oZ_
extern thread_local unsigned t_somevar;
void fn()
{
t_somevar++;
}
看看代码。我们有一个声明的变量,我们对它进行递增。
# -O3 (no demangle)
_Z2fnv: # @_Z2fnv
pushq %rax
movl $_ZTH9t_somevar, %eax
testq %rax, %rax
je .LBB0_2
callq _ZTH9t_somevar
.LBB0_2:
movq t_somevar@GOTTPOFF(%rip), %rax
addl $1, %fs:(%rax)
popq %rax
retq
_ZTW9t_somevar: # @_ZTW9t_somevar
pushq %rax
movl $_ZTH9t_somevar, %eax
testq %rax, %rax
je .LBB1_2
callq _ZTH9t_somevar
.LBB1_2:
movq %fs:0, %rax
addq t_somevar@GOTTPOFF(%rip), %rax
popq %rcx
retq
# -O3 (demangled)
fn():
pushq %rax
movl $thread-local initialization routine for t_somevar, %eax
testq %rax, %rax
je .LBB0_2
callq thread-local initialization routine for t_somevar
.LBB0_2:
movq t_somevar@GOTTPOFF(%rip), %rax
addl $1, %fs:(%rax)
popq %rax
retq
# Aieeeee!实际重复!
thread-local wrapper routine for t_somevar:
pushq %rax
movl $thread-local initialization routine for t_somevar, %eax
testq %rax, %rax
je .LBB1_2
callq thread-local initialization routine for t_somevar
.LBB1_2:
movq %fs:0, %rax
addq t_somevar@GOTTPOFF(%rip), %rax
popq %rcx
retq
看看汇编。开头有一些魔法,一些对某些符号的调用,下面也发生了一些事。在 Godbolt 中可以做什么让生活轻松一点,能更多地理解正在发生的事情呢?这里有一个很棒的功能叫“demangle”(反重整),它把名字转换成更易读的形式。我们立刻看到了一些奇怪的函数名,比如 _ZTH... 和 _ZTW...,以及对这些奇怪函数的调用。从上下文中可以理解,initialization 暗示我们应该初始化某些东西,而 wrapper 呢,它应该包装我们的代码。
实际上,如果你看主代码和开头的初始化代码,它们在 wrapper 中是精确重复的。也就是说,wrapper 实际上是一个精确的副本,它返回给我们指针。
# -Oz
fn():
pushq %rax
callq thread-local wrapper routine for t_somevar
# 我们的加一操作
incl (%rax)
popq %rax
retq
thread-local wrapper routine for t_somevar:
pushq %rax
movl $thread-local initialization routine for t_somevar, %eax
testq %rax, %rax
je .LBB1_2
callq thread-local initialization routine for t_somevar
.LBB1_2:
movq %fs:0, %rax
addq t_somevar@GOTTPOFF(%rip), %rax
popq %rcx
retq
我们可以使用 Clang 的一个编译选项 -Oz,它能让代码更紧凑,内联更少,这会稍微简化我们的生活。
在 -Oz 下,我们看到开头的魔法代码消失了,直接变成了对 wrapper 的调用。编译器最初生成了 wrapper,并在这里调用了它。后来,由于编译器喜欢优化,它在这里内联了 wrapper。所以我们既有 wrapper 的副本,又有内联的版本。通过 rax 寄存器返回了指向我们 thread_local 变量存储位置的指针,然后我们对它进行了递增。
但我们如何理解这个初始化器(initializer)是什么,如何看到它的代码呢?为此,我们稍微修改一下源代码。
extern unsigned f();
thread_local unsigned t_somevar = f();
void fn()
{
t_somevar++;
}
我们有一个 unsigned 变量,我们给它一个动态初始化,即通过调用一个在别处定义的函数来初始化。根据标准,当代码访问这个变量时,我们必须执行初始化器,也就是调用这个函数。
fn():
pushq %rax
callq thread-local initialization routine for t_somevar
incl %fs:t_somevar@TPOFF
popq %rax
retq
thread-local wrapper routine for t_somevar:
pushq %rax
callq thread-local initialization routine for t_somevar
movq %fs:0, %rax
leaq t_somevar@TPOFF(%rax), %rax
popq %rcx
retq
thread-local initialization routine for t_somevar:
pushq %rax
cmpb $0, %fs:__tls_guard@TPOFF
je .LBB2_1
.LBB2_2:
popq %rax
retq
.LBB2_1:
movb $1, %fs:__tls_guard@TPOFF
callq f()
movl %eax, %fs:t_somevar@TPOFF
jmp .LBB2_2
t_somevar:
.long 0 # 0x0
# 新增的守卫
__tls_guard:
.byte 0 # 0x0
现在让我们看看代码本身。这里会出现初始化器。初始化函数本身做了什么?它出现了一个额外的对象,实际上是一个 byte 类型的变量,它显然也是 thread_local 的。简单来说,这是一个布尔类型,它也是 thread_local 的,并且它是一个守卫(guard)。这有什么用?就像单例模式如何工作一样,我们有一个标志。第一次通过时,我们检查它是否为零。是的, значит 我们需要初始化对象。我们进行初始化,然后设置标志,表示一切都已初始化。下次进入时,我们只需要检查对象是否已初始化。如果已经初始化,我们什么都不用做。
这个 thread_local 变量实际上我们在代码中是看不到的,但它确实存在。在开头,我们检查它的值,如果已初始化,就直接返回。如果未初始化,我们接下来就设置这个标志,表示“正在初始化”。然后我们调用真正的初始化函数,并获取地址。
但这里有一个有趣的时刻。还记得我强调的吗?标准说,如果在初始化时抛出异常,初始化应被视为未完成,下次必须重试。但我认为,这里其实是编译器的一个 bug。因为它在调用函数之前就把标志设置为“已完成”了。他们很可能是想通过这种方式解决标准中提到的循环依赖(重入)问题,但却违反了标准关于异常情况下需要重试初始化的规定。如果发生异常,将不会有第二次初始化。所以,如果你要比较编译器的行为和标准,请注意,唉,就是这样。
好的,关于这段代码,我想说的就这么多了。
我们来总结一下。我们出现了两个用于 TLS 的函数:
_ZTH...(TLS Init Function):这是初始化函数。它们是弱符号。这是什么意思?如果我们使用一个在别处声明的变量,我们不知道它是否已初始化。因此,我们首先请求链接器为我们放置这个弱函数的地址。如果它找到了,它就放置我们必须调用的初始化函数的地址。如果没有,那里就是零。在包装器中,开头检查init_function的那段代码做的正是这件事:它检查我们是否有初始化函数。如果有,我们就调用它。_ZTW...(TLS Wrapper):这是我们的包装器,它实际上是编译器生成的代码的来源。编译器总是保留它们,因为可能另一个目标文件是用-Oz之类的选项编译的,它会尝试寻找这些包装器,并通过它们来访问thread_local变量。
// https://godbolt.org/z/hhaYmq
// -Oz
#include <stdio.h>
class SomeCls
{
public:
SomeCls();
~SomeCls();
void increment();
private:
int m_count = 0;
};
thread_local SomeCls t_scls;
int main(int argc, char** argv)
{
t_scls.increment();
return 0;
}
让我们看一个关于对象的例子。毕竟我们 активно地使用 C++,对象在某种意义上是 C++ 的精髓。
我们有一个类,它有在别处定义的构造函数和析构函数,一个非平凡的例子。我们还有一个 increment 函数,它也定义在别处并做一些事情。thread_local 对象在全局作用域声明,我们在 main 中调用它的 increment 函数。
main: # @main
pushq %rax
callq _ZTH6t_scls
movq %fs:0, %rax
leaq t_scls@TPOFF(%rax), %rdi
callq _ZN7SomeCls9incrementEv
xorl %eax, %eax
popq %rcx
retq
_ZTW6t_scls: # @_ZTW6t_scls
pushq %rax
callq _ZTH6t_scls
movq %fs:0, %rax
leaq t_scls@TPOFF(%rax), %rax
popq %rcx
retq
_ZTH6t_scls: # @_ZTH6t_scls
pushq %rbx
# 判断需要 guard 初始化而跳入 .LBB2_2
cmpb $0, %fs:__tls_guard@TPOFF
je .LBB2_2
popq %rbx
retq
.LBB2_2:
movb $1, %fs:__tls_guard@TPOFF
movq %fs:0, %rax
leaq t_scls@TPOFF(%rax), %rbx
# 调用构造函数,并为 atexit 注册填入一系列参数
movq %rbx, %rdi # this,给构造函数和退出注册用
callq _ZN7SomeClsC1Ev # 调用构造函数
movl $_ZN7SomeClsD1Ev, %edi # 析构函数(第一个参数)
movl $__dso_handle, %edx # __dso_handle(第三个参数)
movq %rbx, %rsi # this(第二个参数)
popq %rbx
jmp __cxa_thread_atexit # TAILCALL
t_scls:
.zero 4
__tls_guard:
.byte 0 # 0x0
在初始化器中发生了什么?和之前一样,检查守卫。如果需要初始化,我们再次设置守卫标志(同样,在调用构造函数之前)。然后我们做同样的事情获取 thread_local 变量的地址。此时我们知道,这个 thread_local 变量是一个对象,指向它的指针实际上就是 this 指针。
接下来,我们为一个有趣的函数准备参数:__cxa_thread_atexit。我们都知道 atexit 函数,如果我们想在程序结束时调用一些回调,我们会注册它们。__cxa_thread_atexit 也是类似的功能,但它是为线程准备的,它会为我们清理析构函数。析构函数的调用顺序与构造相反。
它是如何工作的?在一个专门用于 atexit 的栈上,我们注册:
- 析构函数本身。
- 我们的
this指针。 - 还有一个小东西
__dso_handle,这是它所在模块的唯一标识符。这很重要,因为动态对象也可能被单独卸载。
然后我们将这些信息通过寄存器传递给一个函数,该函数将它们注册到栈上。当线程的主函数退出时,所有这些析构函数会带着它们的 this 指针被依次调用。
总结一下:
- 对象在首次访问时进行初始化,与动态初始化类似。
- 为对象和动态初始化创建额外的守卫变量。
- 对于对象,会额外调用
__cxa_thread_at_exit来注册将在线程退出后调用的析构函数。
还有一个重要的规则,源自标准:我们不应该混合静态对象和 thread_local 对象的析构。例如,我们有全局对象,它们的析构函数使用了 thread_local 对象。这种情况只有在一种情况下可能发生:如果所有 thread_local 对象都已经被销毁了,因为它们的销毁 happens-before 静态对象的销毁。
在 main 函数之后,开始销毁全局对象。如果此时我们访问一个 thread_local 变量,一开始当然一切正常,它会被调用,它的析构函数也会被放入那个神奇的栈中。但是,已经没有人来调用它了,因为线程本身已经被销毁了。我们无法期望它的析构函数会被调用,它就是不会被调用。这完全符合标准,即未定义行为。
新模型:描述符模型 (Descriptor Model)
那么,接下来呢?上面说的是经典模型,我们看到它在各种复杂情况下有很多不理想之处。编译器开发者自然开始思考可以做些什么。这里有一篇 Alexandre Oliva 的论文,我推荐阅读,如果你想让大脑骨折的话,因为里面描述得相当复杂。如果你想先看简单点的,可以在 Android 文档中找到一个更直观地展示所有这些想法的文档。
Дескрипторная модель
- В GOT можно хранить указатель на функцию резолвер
- Линкер может выбирать наиболее оптимальный вариант резолвера
描述符模型
- 可在全局偏移表(GOT)中存储指向解析器函数的指针
- 链接器能够选取最优化的解析器实现方案
文档中所谓的描述符模型(Descriptor Model)的核心思想是什么?我们可以继续使用 GOT,但方式不同。我们可以把某种函数式编程的思想应用进来。我们可以在 GOT 中为我们的对象放置一个解析器(resolver)函数,这个函数可以根据我们处理的情况而改变。旁边再放一个参数。解析器函数的输出就是 thread_local 变量的地址。
我们要明白,当动态加载器工作时,它对加载的代码有更多的了解:动态对象在哪里,它们的存储区在哪里,是在静态 TLS 还是动态 TLS 中。它可以做更多优化。
那它是如何工作的?
struct TlsDescriptor { // NB: arm32 reverses these fields
long (*resolver)(long);
long arg;
};
我们有新的重定位类型 TLSDESC(描述符)。它指向一个结构,包含解析器函数的地址和传递给解析器的参数。
char* get_tls_var() {
// allocated in the .got, uses a dynamic relocation
static TlsDescriptor desc = R_TLS_DESC(tls_var);
return (char*)__get_tls() + desc.resolver(desc.arg);
}
链接器在加载程序时会设置这个解析器,并根据情况选择对你来说最廉价的方案。工作流程很简单:
- 通过重定位获取 GOT 中描述符的地址。
- 调用解析器函数。
- 将结果与我们的 TLS 基地址相加。
long static_tls_resolver(long arg) {
return arg;
}
接下来是一个解析器的例子,当 thread_local 变量的偏移量是预先知道的时,链接器会放入这个最简单的解析器,它直接返回传递给它的参数(即偏移量),我们马上就能得到最终地址。非常简单。
需要注意的是,这些解析器有非标准的 ABI。它们通过 rax 寄存器接收唯一的参数(指向 GOT 条目的指针),而不是通常的 rdi。这是为了节省寄存器。
// https://godbolt.org/z/-jZR4r
// -Os -fpic -mtls-dialect=gnu2
extern thread_local int t_glob;
void fn()
{
t_glob++;
}
我们可以使用 -mtls-dialect=gnu2 来尝试这个。它已经在 GCC 中完全实现,在 Clang 中目前只支持 AArch64。但我们可以在 GCC 中看到它。
(人工注:2024 年的进展。总之 Clang 19 能处理该选项。)
fn():
pushq %rdx
cmpq $0, _ZTH6t_glob@GOTPCREL(%rip)
je .L2
call thread-local initialization routine for t_glob@PLT
.L2:
leaq t_glob@TLSDESC(%rip), %rax
call *t_glob@TLSCALL(%rax)
incl %fs:(%rax)
popq %rax
ret
看下汇编。我们同样检查并调用初始化器。然后是实际工作部分:
rax寄存器获取指向 GOT 中描述符的指针(相对于当前执行位置)。这是解析器的输入。- 从 GOT 中获取解析器函数的地址并调用它。
- 解析器返回一个相对于 TLS 基地址的偏移量到
rax。 - 我们知道基地址(
fs),就可以得到最终地址。
这里可以有非常智能的解析器。在最坏的情况下,如果库是通过 dlopen 加载的,并且有自己的动态 TLS,解析器可能会再次调用 __tls_get_addr。但如果它在加载时被放入了静态 TLS,这里就会是另一个更廉价的解析器。
这种实现真正有趣的是,我们可以在数据层面实现延迟绑定。这在很大程度上是首创。通常链接器会预先链接好数据,而函数是延迟链接的。在这里,我们可以实现 thread_local 变量的延迟链接。当然,这会引入并发问题,需要用一些技巧,比如替换假的解析器、使用条件变量等。如果你感兴趣,可以去看看 Glibc 的源码,那将是非常有趣的读物。
我认为这个模型最有前景,希望它能尽快登陆 x86,并解决一些性能上的痛点。
基准测试
我使用了 Docker,因为我的机器是 Mac,但我在真机上验证过,比例关系基本一致。基准测试非常简单,就是各种递增操作。为了对比,我加入了静态变量。
static变量initial-execlocal-execlocal-dynamic(DSO)general-dynamic(DSO)- POSIX
pthread_getspecific - POSIX
pthread_getspecific+pthread_setspecific
我编译了代码,然后运行 benchmark。它会运行相当长的时间,我认为这具有代表性。需要说明的是,这里有误差,也有与编译相关的误差。
root@docker-desktop:/source/Speech/tls_speech/bench# make
rm -f bench *.o *.so *.dylib *.asm perf.data*
clang++ --shared -fpic -std=c++17 -Os -I/usr/local/include -march=native -L/usr/local/lib -lbenchmark \
dso.cpp -o libdso.so
objdump -S libdso.so >dso.asm
clang++ -c -std=c++17 -Os -I/usr/local/include -march=native bench.cpp -o bench.o
clang++ bench.o -L. -Wl,-rpath,. -ldso -L/usr/local/lib -lbenchmark -lpthread -o bench
objdump -S bench >main.asm
root@docker-desktop:/source/Speech/tls_speech/bench# ./bench
2020-07-01 08:50:57
Running ./bench
Run on (4 X 2727.93 MHz CPU s)
CPU Caches:
L1 Data 32K (x4)
L1 Instruction 32K (x4)
L2 Unified 256K (x4)
L3 Unified 6144K (x4)
L4 Unified 131072K (x4)
Load Average: 0.00, 0.00, 0.00
---------------------------------------------------------------
Benchmark Time CPU Iterations
---------------------------------------------------------------
BM_LocalDynamic 3.31 ns 3.31 ns 216409665
BM_GeneralDynamic 4.31 ns 4.31 ns 166270784
BM_Static 2.94 ns 2.92 ns 240023426
BM_InitialExec 2.87 ns 2.86 ns 238094590
BM_LocalExec 3.09 ns 3.08 ns 228764001
BM_PthreadSpecificGet 11.9 ns 11.9 ns 59046865
BM_PthreadSpecificInc 26.9 ns 26.8 ns 26387591
我们的参考基准是静态全局变量的访问,耗时 2.94 ns。
Initial-exec不知为何稍微快一点,但实际上是因为我没能让 Clang 不做循环不变量代码外提(loop-invariant code motion),导致对 GOT 的访问被移出了循环,所以我们没测到它。Local-exec稍慢一些,但在误差范围内。可以说,当它在可执行文件中时,与访问静态数据的开销大致相当。- 接下来自然是
local-dynamic,动态库中更廉价的模型。 - 最重量级的是
general-dynamic。 - 更不用说
pthread_getspecific,当我们只获取不设置时,以及获取、递增、再设置时,它是最慢的。
我们可以看到,使用关键字已经带来了巨大的好处。我想强调,对待这些基准测试要非常小心。因为我们在这里是持续访问 thread_local,分支预测器已经完全学习了模式,它的预测表(PHT, BHT 等)几乎是 100% 命中,缓存也是热的。如果是在稀疏访问 thread_local 的情况下,我们很可能两样都没有。这里的数字可能需要乘以某个因子,才能反映出更真实的计算复杂度。但在真机上,比例关系大致如此,我想在真实场景中也差不多。
总结
让我们回顾一下今天我们看了什么:
- POSIX
pthreads可能已经过时,但它们仍被积极使用,甚至在抛出异常时也会用到这个机制。 thread_local是一个相当高效的机制,但它仍在发展中。你看,并非所有架构都实现了所有可能的变体,尤其是在动态库方面。macOS 也是如此。我认为在其他平台上也差不多。这里还有发展的空间,甚至可以自己去贡献代码。- 我想总结一下,
thread_local的位置在哪里?实际上,thread_local是一种代码耦合机制,就像它的近亲——全局变量一样。我们使用越多的thread_local,代码的耦合度就越高。我们都知道,拥有解耦的代码是好事,有独立的组件和类,它们执行自己狭窄的特定任务,它们之间了解得越少,我们的代码就越容易维护,效率也越高。但代码不能悬在空中,我们需要一些链接机制。 - 对我个人而言,我得出的结论是:
thread_local是一种链接机制。它应该位于其节点中,为我们提供比全局对象和变量更轻量级的链接方案。我认为这才是它的正确位置。我不建议过度使用thread_local,它们有自己的“栖息地”,在那里它们非常出色。
在此,我想表示感谢,并为一些小的技术问题道歉。这里是我的联系方式,我随时准备提供帮助,回答任何问题。所以,欢迎大家。